【论文阅读(一)】A Survey of Clustering With Deep Learning From the Perspective of Network Architecture
导语:这是2018年发表在IEEE ACCESS上的一篇用深度学习来做聚类的综述论文,该综述论文从网络结构的角度回顾了利用深度学习实现无监督聚类的发展
摘要
在很多数据驱动的应用领域中聚类是重要的问题之一,聚类的性能高度依赖数据的表示。因此,线性或非线性特征变换被广泛地聚类,用于学习更好的数据表示。在最近几年,大量的工作聚焦于使用深度神经网络去学习聚类友好的表示,极大促进了聚类的性能。在本文作者从网络结构的层面对基于深度学习的聚类算法进行了一个系统的回顾。为了更好地理解该领域,作者首先介绍了基础知识。然后对深度学习地聚类算法进行了分类,并且介绍了各个类别中地一些代表性方法。最终,作者提出了一些用深度学习实现聚类的机遇和给出了一些结论。
背景
数据聚类在很多领域中是一个基础性问题,如机器学习、模式识别、计算机视觉、数据压缩。聚类的目标在于按照基于某种相似性度量,将相似的数据归类到同一组。尽管已经有了大量的数据聚类方法。传统聚类算法在高维数据上的表现通常很差,这是因为这些传统方法的相似度衡量方式对高维数据不管用。此外,通常这些方法在大规模数据集上面临很高的计算复杂度。基于上述原因,降维和特征变换方法被广泛地研究用于将原始数据映射到新的特征空间,这些特征空间的生成数据很容易被当前的分类器分类。通常来说,现存的数据变换方法包括线性变换,如PCA和非线性变换如核方法和谱方法。尽管如此,高复杂潜在结构的数据仍然是现存聚类方法的一个挑战。由于深度学习的发展,由于DNN的高非线性变换内在属性,其被广泛地应用到将数据转换到更容易聚类的表示。为了简单表示,下文将用深度学习实现聚类的方法称为“深度聚类(deep clustering)”。
目前的工作主要集中在特征变换或者独立性聚类中。通常数据要映射到一个特征空间并直接喂入一个聚类算法。最近几年内深度嵌入聚类(DEC)被提出并且有很多改进版本,使得深度嵌入称为研究的新热点。
经典的聚类方法通常被分类成基于分割的方法、基于密度的方法和基于层级的方法。然而,深度聚类的本质是学习更容易聚类的表示,它并不适合根据聚类损失的分类,相反更应该注意用于聚类的网络结构。作者将从以下三个方面的网络结构对现有无监督学习方法进行分类。
- 第一类使用自编码器(AE):用AE来获得可靠的特征空间。自编码器网络通过编码器和解码器提供了一种非线性映射函数,编码器是需要训练的映射函数,解码器将重建编码器输出的特征至原始图像。
- 第二类是基于前向网络,聚类DNN(CDNN):仅使用特殊的聚类损失训练网络。此类网络的结构可以很深,从其他大规模数据集上预训练的网络可以促进聚类的性能。
- 第三类和第四类分别是基于GAN和VAE的。他们不仅适合聚类任务,也能从其他得到的聚类中生成新的样本。
基础知识
这部分将介绍特征表示的网络结构、标准聚类方法的损失函数和深度聚类的评估指标。
网络结构
- 前馈全连接网络:FCN是有多层神经元组成的,每个神经元都与前一层的神经元有连接,且每个连接都有其权重。FCN也可以称为多层感知机(MLP)。连接模式没有假设数据中的特征,这种方法在监督学习中广泛存在。然而,对于聚类而言,一个好的网络参数初始化对于一个初始FC网络是必要的,这是因为当所有的数据点都被简单地映射到紧凑地聚类,这样网络学到地东西就很有限,这将会造成很小的聚类损失,与预设相差很大。
- 前向卷积神经网络:卷积神经网络启发自生物过程,神经元之间的连接模式受启发自动物器官的视觉突触。与此相似,卷积层中的每个神经元仅与前一层的附近几个神经元相连。当需要特征提取的局部性和平移不变性时,它被广泛应用于图像数据集。 可以直接针对特定的群集丢失进行训练,而无需任何初始化要求,良好的初始化将显着提高群集性能。在目前任何发表的论文中,没有理论分析,但是很多工作证明其可用于聚类。
- 深度信念网络(Deep Belief network):DBN生成图模型,其从输出数据中提取深层级的表示。DBN网络由受限制玻尔兹曼机器(RBM)堆叠而成。贪婪的逐层无监督训练适用于以RBM为每一层的构建块的DBN。 然后,相对于某些标准(损失函数),例如DBN对数似然的代理,监督训练标准或聚类损失,微调DBN的所有(或部分)参数。
- 自编码器(AutoEncoder):在无监督表示学习中,AE是最重要的算法之一。它是训练映射函数的强大方法,其保证了编码层和数据层之间的最小化重建损失。因为隐藏层的维度比数据层更少,这有助于找到数据的显著特征。尽管在简单学习中,自编码器常被用于寻找更好的初始化参数。
- GAN&VAE:GAN旨在生成器和判别器之间达到平衡,而VAE旨在最大化数据对数似然的下界。对GAN和VAE模型进行一系列拓展。它们也被用于处理聚类任务。
聚类相关的损失函数
该部分介绍了聚类损失函数,损失函数可以知道网络学到更有助于聚类的表示。通常而言,有两种聚类损失:
- 主聚类损失(Principal Clustering Loss):这类聚类损失函数包括聚类质心和样本的聚类分配。换句话说,在由聚类损失训练完网络后,可以直接得到聚类。这类损失包括K-mean损失,聚类分配硬损失,聚集聚类损失和非参数最大边界聚类损失
- 辅助聚类损失(Auxiliary Clustering Loss):第二类损失仅仅扮演了可以指导网络学习到更可靠的聚类表示,但是无法直接得到聚类。这意味着使用辅助聚类损失的深度聚类方法需要在训练完网络后再次运行模型,才能得到聚类。在深度聚类中,有很多辅助聚类损失,如
- locality-preserving loss(保留局部损失):这迫使网络保留数据嵌入的局部属性。
- group sparsity loss(组稀疏损失):利用块对角相似矩阵进行表示学习
- sparse subspace clustering loss(稀疏子空间聚类损失):目的在于学习到数据的一种稀疏编码。
深度聚类的性能评估指标
在很多深度聚类论文中有两个标准的无监督评估指标。在所有的算法中,类别的数量被设置为真实聚类。
- 第一个指标为无监督聚类准确率:
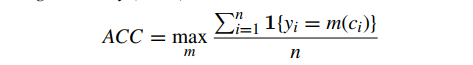
其中yi是真实标签,ci是由算法生成的聚类;m是映射函数,用于分配和标签之间所有可能的一对一映射范围。显而易见的是,该指标可以发现由聚类算法生成的聚类与真实类别的最佳匹配。最优映射函数可由Hungarian 算法得到。
-
第二个指标是正规化互信息(Normalized Mutual Information, NMI)
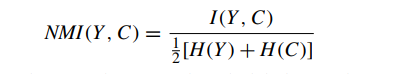
其中Y表示真实标签,C表示聚类标签,I是互信息指标,H是熵。
深度聚类的分类
总结如下表所示
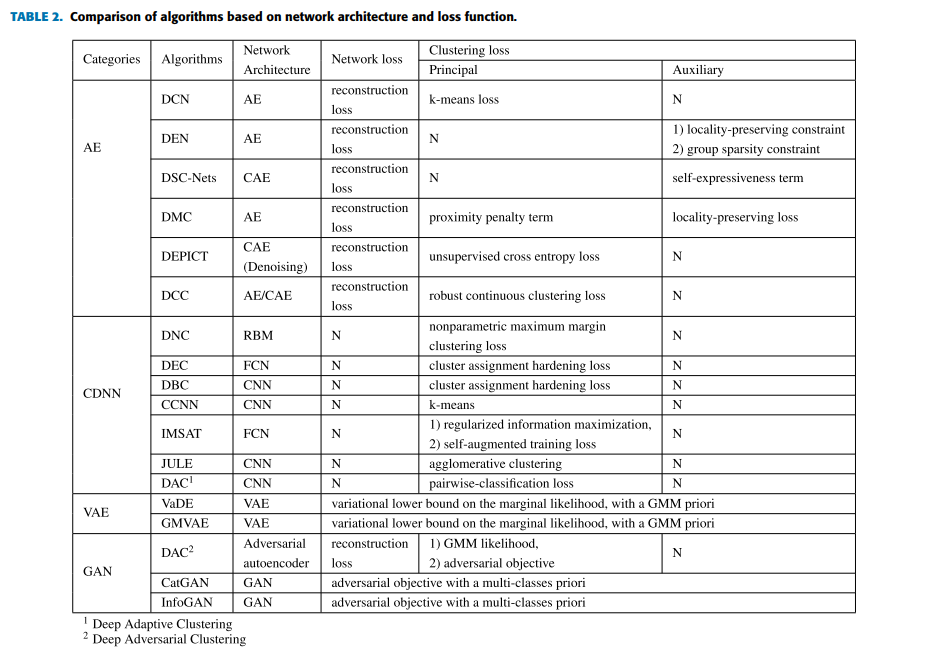
各个方法的共享在于
-
基于自编码器AE的深度聚类算法:网络结构如下
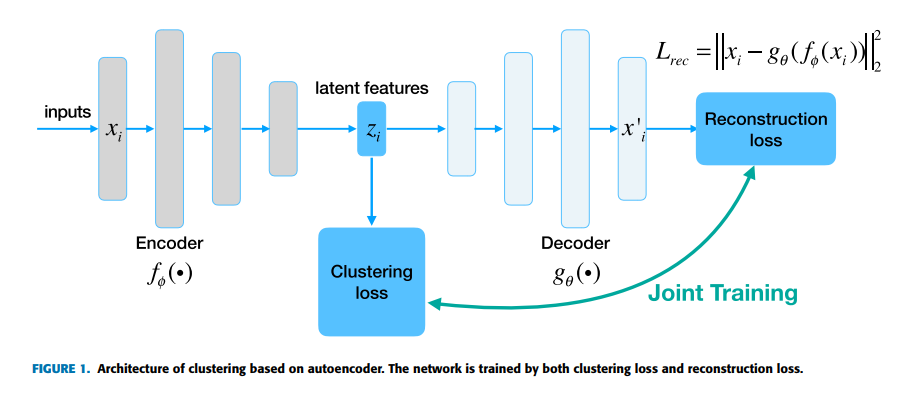
-
基于CDNN深度聚类的算法:网络结构如下
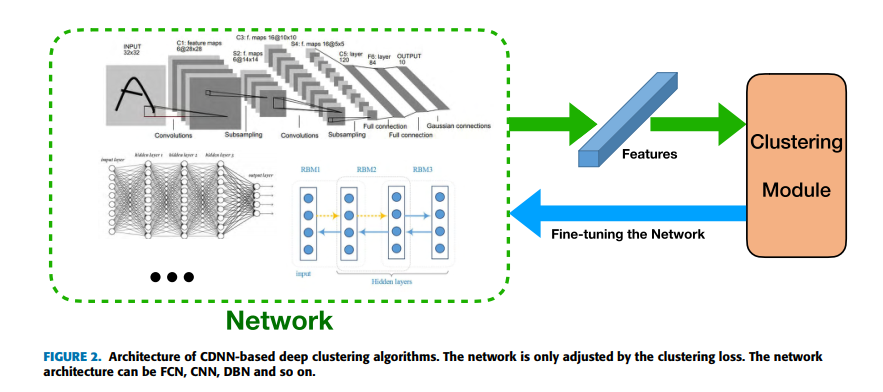
-
基于VAE深度聚类算法:网络结构如下
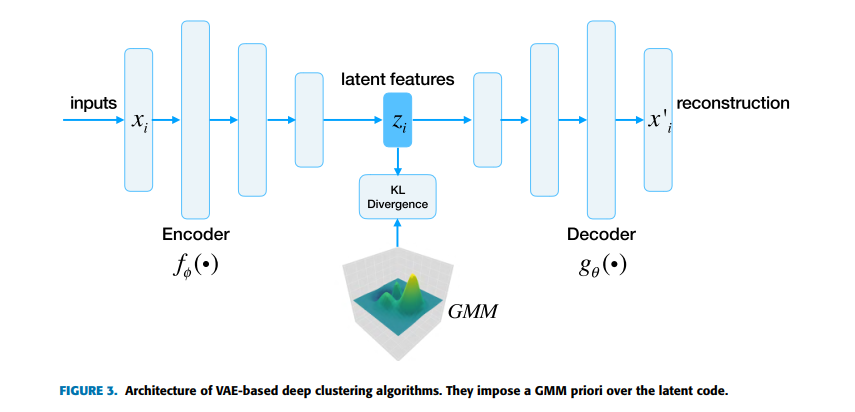
-
基于GAN深度聚类算法:网络结构如下
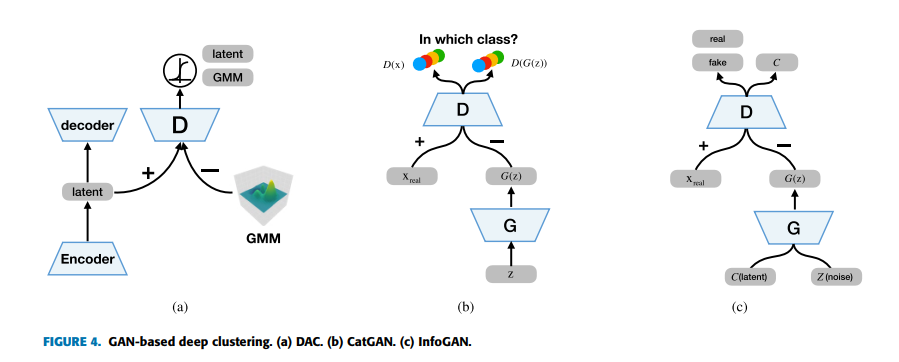
深度聚类算法的总结
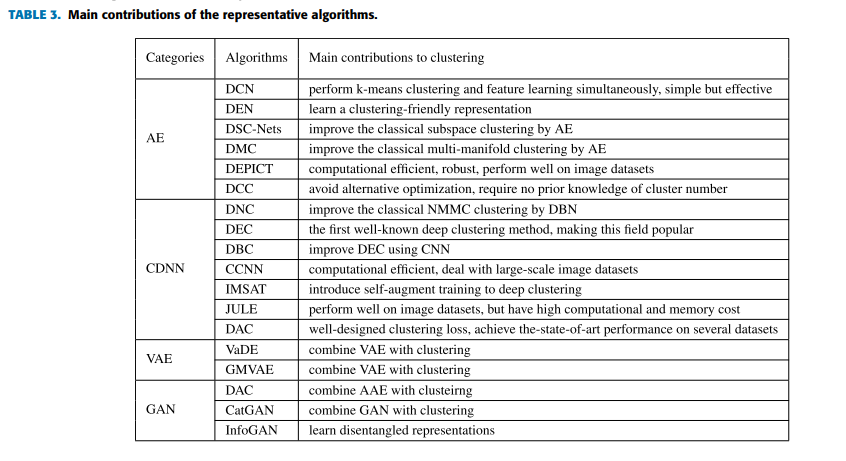
各类算法的总结如下表所示:
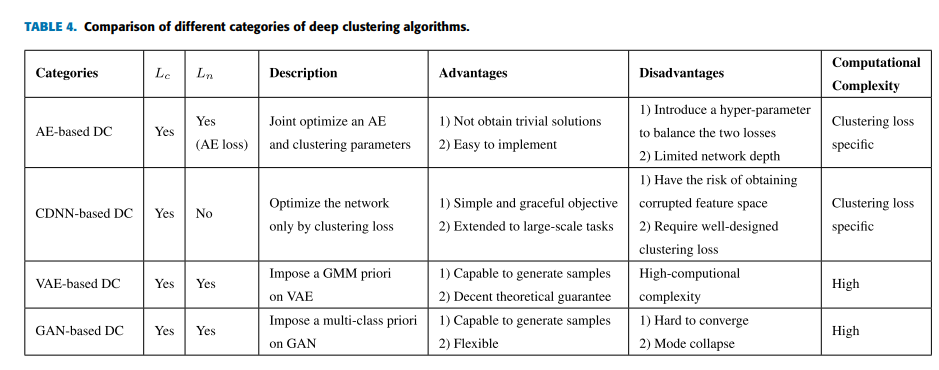
结论如下:
- 除了基于CDNN算法外,其他三类算法联合优化聚类损失和网络损失。差异在于AE-based中的网络损失是重建损失,而VAE和GAN算法通常是合并在一起。
- 基于AE的DC算法最常见的自编码器几乎可以与所有的聚类想法组合。
- 基于CDNN的DC算法深层网络的计算复杂度很高,因此其深度是有限的,并且监督的预训练结构可以用于提取更具判别性的特征。然而,没有重建损失,有学习到无效特征表示的危险,因此聚类损失要很仔细的设计。
- VAE和GAN的DC算法可以从学习到的聚类中生成样本。VAE算法有较好的理论解释,因为他们在数据边际似然最小化变分下界,但是计算复杂度很高。GAN算法在通用GAN施加了多类别先验,GAN算法比VAE算法更灵活、更加多样化。他们中的一些目的在学习可解释性表示,将聚类作为特殊例子。缺点在于容易崩溃和收敛很慢。
- AE和CDNN方法的计算代价与聚类损失高度相关。
未来机遇和结论
-
理论探索
-
其他网络结构
图像转向其他序列数据,如文档。使用RNN处理文档聚类
-
深度学习的技巧
数据增强、特定正则化。用噪声增强的数据提高聚类方法的鲁棒性。
-
其他聚类任务
多任务聚类、迁移聚类。