【对抗样本(一)】Dual Attention Suppression Attack Generate Adversarial Camouflage in Physical World
导语:
arXiv: https://arxiv.org/pdf/2103.01050.pdf
github: https://github.com/nlsde-safety-team/DualAttentionAttack
摘要
近年来,物理对抗样本作为一种对实际深度学习更加有危险的类型得到了更加广泛的研究。然而,在不利用模型不可知和人类特定模式等内在特征的情况下,当前的工作在物理世界中产生微弱的对抗性扰动,无法跨不同模型进行攻击,并显示出视觉上可疑的外观。受注意力反映认知过程的内在特征观点的启发,本文提出了双注意力抑制(Dual Attention Suppresion, DAS)攻击,通过抑制模型和人类注意力来生成强大可转移性的视觉物理对抗性迷彩。至于攻击,作者通过将模型共享的相似注意力模式从目标区域转移到非目标区域来生成可转移的对抗性伪装。同时基于人类视觉注意力通常聚焦于显著项(可疑失真),作者避免人类特定的自底向上的注意力模式来生成视觉上更加自然的迷彩,迷彩与场景上下文有关。经过大量的数字和物理世界中分类和在SOTA模型(YOLO-V5)检测任务的实验证明了方法的优于SOTA。
介绍
过去的几年中,在不同场景的不同设置下,大量的工作被提出来实现对抗攻击。通过挑战深度学习,对抗样本对于理解DNN的行为同样具有价值,也能提供对深度学习盲点的insights并且有助于建立鲁棒的模型。通常,对抗攻击可以分成以下两类:
- 数字攻击:在数字空间内,通过扰动输入数据攻击DNN模型;
- 物理攻击:在物理世界中,通过修改真实物体的视觉特征攻击DNN模型。
与数字世界的攻击相比,物理世界的攻击更具挑战性,这可能是因为物理世界约束和条件(如:光线、距离、相机等),这些因素会影响生成对抗扰动的攻击能力。在本文,作者主要聚焦于更具挑战的物理世界攻击,这对在实际中部署的深度学习应用更有意义。
目前已经有很多实现物理攻击的尝试的了[31,19,30],现有的工作通常忽视内在特质如模型不可知和人类特定模式,这使得这些攻击的能力达不到满意的结果。实际上,限制可以总结成以下几点:
- 现有的方法忽视了模型间常见的模式以及使用模型特定线索来生成对抗扰动,这将导致无法跨不同目标模型进行攻击。换句话说,对抗扰动的可转移性很微弱,这将会影响他们在物理世界中攻击能力。
- 目前方法生成对抗扰动会带有视觉可疑外观,这与人类的感知能力差强人意,甚至引起了人类的注意。例如,在对抗性伪装上绘制【19】。然而,如下图所示,伪装的外观包含了不自然和可疑的鸟类相关特征(如,鸟的头),这会吸引人类的注意力。
为了接近上述提到的问题,本文提出了DAS攻击,通过同时抑制模型和人类注意力。考虑到攻击的可转移性,受到生物观测发现,遇到刺激特征时,不同个体之间的大脑活动具有相似的模式。(选择注意力),作者通过抑制不同模之间共享的注意力模式。具体来说,作者通过连接图将模型共享的相似注意力从目标区域分散到非目标区域。因此,目标模型将不会将注意力指向目标区域的物体,而造成误分类。因为作者生成的对抗性伪装捕获了模型认知结构,它可以迁移到不同模型,这提高了可转移性。
至于视觉不自然性,心理学家发现人类视觉的是自底向上的注意力会提醒人们注意显著的物体(如失真)。当前方法生成的物理对抗样本带有视觉可疑外观,这显示人类感知的显著特征。因此,作者尝试通过生成包含与场景环境相关的高级语义关联的对抗性伪装来避免这种人类特定的视觉模式。结果是生成的伪装在人类感知上更不容易生疑和自然。

作者自己认为的创新:作者认为他们是第一个提出利用共享模型间的注意力特点通过抑制模型和人类注意力,生成物理世界的对抗性伪装。
相关工作
基于对抗扰动生成的领域,攻击分成数字攻击和物理攻击。
- 数字攻击:在数字像素领域,为输入生成对抗性扰动。Madry等人提出的PGD算法是目前最强的一介扰动攻击方法。当将这类攻击应用到物理世界中时,攻击能力会极大下降。
- 物理攻击:物理攻击旨在通过修改物理世界中真实物体的视觉特征来生成对抗性扰动。为了实现该目标,很多工作首先在数字世界生成对抗性扰动,然后通过在真实物体上绘上对抗性伪装或直接创造对抗性物体。
- 通过构造绘制函数,Athalye等人[2]生成了3D对抗性物体在物理世界攻击分类器。
- Eykholt等人将NPS[33]引入损失函数,这损失函数考虑了制造错误以至于他们能够生成强大对抗性攻击,攻击交通标志识别。
- 最近,Huang等人[19]提出了Universal Physical Camouflage Attack(通用物理伪装攻击,UPC),通过联合愚弄提出网络区域和分类器修改伪装。
- 其他工作尝试实现物理对抗攻击来生成对抗性补丁,这将扰动限制到很小和无扰动约束的局部补丁[30,31]。
方法
问题定义
(M,T)表示一个3D真实物体,M为mesh张量,T为纹理张量,$c \in C$为环境条件(相机视角、距离、明亮度),使用渲染函数R来生成图像$I=R((M,T),c)$。构造对抗样本就将$T$替换成对抗性纹理张量$T_adv$,拥有不同的物理属性(颜色、形状)。最后通过$\epsilon$。
框架概览
整体框架如下图所示:
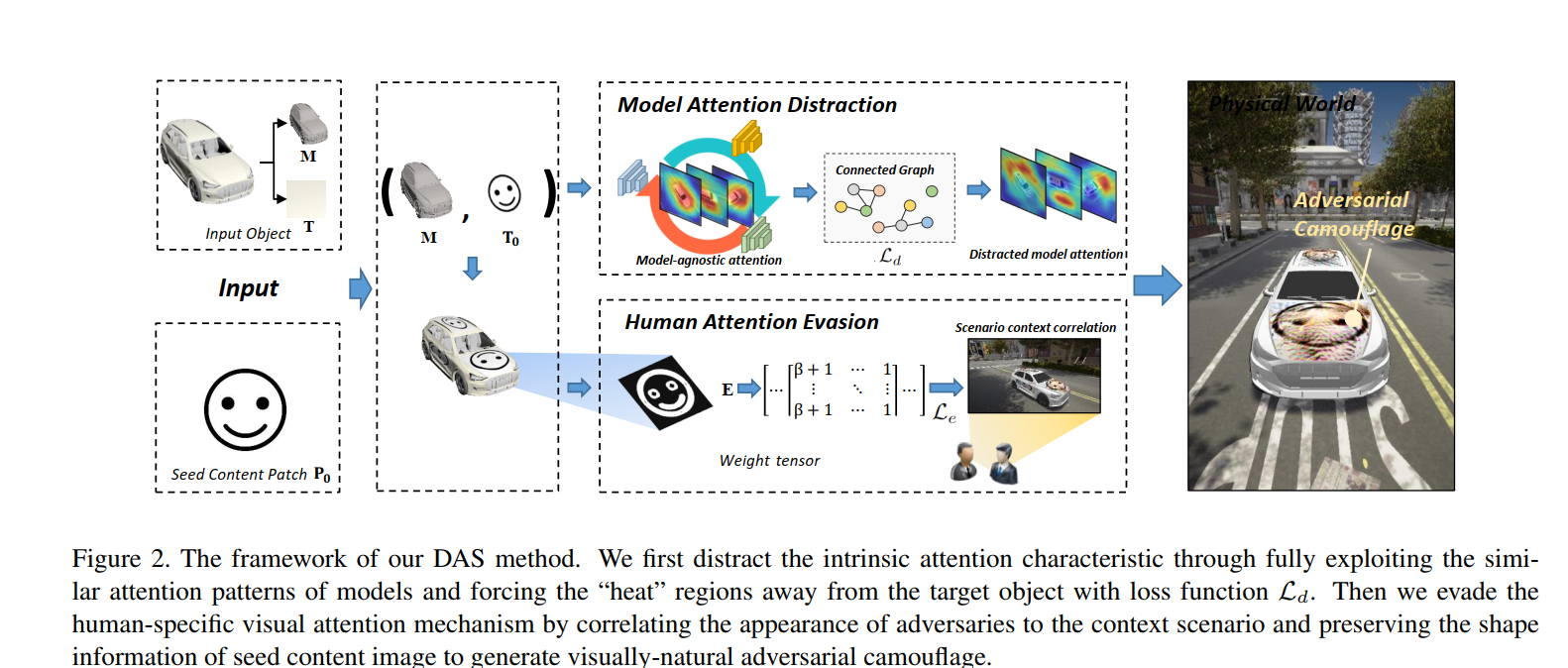
考虑到攻击的迁移性,受生物学观察的启发,抑制了模型间共享的相似注意力模式。具体的,通过连接图将模型注意力从目标区域分散到非目标区域(如,背景)。因为不同深度模型对相同物体会生成相似的注意力模式,生成的对抗伪装可以捕获模型不可认知结构和转移到不同模型。
视觉自然 通过引入种子内容补丁$P_0$,该补丁与场景环境有很强的感知相似性,在这种情况下,生成对抗性伪装能够更加不可疑和对人类感知更加自然。当预测的时候,人类更加注意物体形状[29],进一步保留了种子内容补丁的形状信息来提升人类注意力相关性。因此,很好地避免了人类特定地注意力机制,生成了更自然的伪装。
模型注意力分散
因为ANN是从人类中心神经系统实现的,假设DNN可能有相同特征的假设是合理的,如当做相同的预测时,不同模型在相同物体有相似的注意力模式。
用于提高解释性和理解深度学习模型行为的视觉注意力技术[49]已经得到了很长时间的研究,如CAM[49],Grad-CAM[37],Grad-CAM++[5]。当预测时,一个模型将其注意力集中到目标区域,而不是无意义的部分。直觉上,为成功攻击一个模型,直接将模型注意力从显著物体中分散。换句话说,我们将显著性区域上模型共享的相似性注意力图分散到其他区域,并强制注意力权重在整个图像中均匀分布。因此,模型未能聚焦到目标物体,并做出了错误的预测。
对于一个$T_{adv}$是最优的对抗纹理张量,特定的标签y,通过R得到$I_{adv}$,然后使用注意力模块A计算注意力图$S^y$
$S^y = A(I_{adv},y)$
更精确的,注意力模块A可以表示成
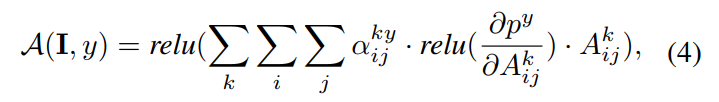
$a^{ky}{ij}$是特定类别y的梯度权重,激活图$k$,$p^y$是类别y的得分,$A^{k}{ij}$是第k个特征图的位置(i,j)处的像素值。注意到注意力模块可以是任意深度学习模型,而不仅仅是目标模型。
接下来是要根据注意力图S,迫使模型的注意力从注意力区域转移到非目标区域。直觉上,注意力图的像素值表示了特定区域对模型预测的贡献。为减少显著物体的注意力权重和分散这些注意力区域,我们利用连接图,这包含图中任意一对节点之间的路径。在图像中,对于每个像素的一个带有注意力权重的区域高于某个特定阈值就可以被认为是连接区域。为了使用连接图分散模型注意力,采用了两个策略:
- 通过将连接图分离成多个子图来减少整体的连接性;
- 减少连接子图中每个节点的权重。
使用了如下的注意力分散损失
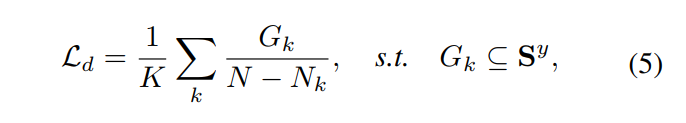
$G_k$是注意力图S中的第k个连接图相关的区域中像素值的和,N是注意力图S中像素总数,$N_k$表示$G_k$中像素总数。通过最小化$L_d$,在注意力图中的显著区域会变得很小(被分散)并且显著图中的像素值会变小(不在“热力”),导致“分散”了注意力图。
人类注意力逃避
为了克服物理世界复杂环境条件带来的问题,很多物理攻击采用加大扰动量的方式。因为自下而上的人类视觉机制通常警醒人们注意显著物体(失真),在这个场景下对抗样本总是会因为显著扰动而引起人类注意,在物理世界中展现出可疑的外观和较低的隐身性。
本文作者目的在于生成视觉上更加自然的伪装,通过抑制人类视觉机制,这将避免人类特定注意力直觉上,我们期望生成的伪装可以与要攻击的上下文共享相似视觉语义(如,与毫无意义的失真相比,在车辆上绘制漂亮的绘画在感知上更容易接受)。因此,生成对抗性伪装与人类感知高度相关,不容易引起人的注意。
特别地,首先合并了一个种子内容补丁P0,它包含与场景上下文地强语义关联。然后将种子内容补丁绘制在车里上,由$T_0= \phi(P_0,T)$。具体地,$\phi (.)$表示是一个转换操作,它首先将2D种子内容补丁转换成3D张量,然后通过张量加法添加到车辆上。
当目光聚焦物体时人类更多地注意到形状,然后做出预测[29],我们目的是通过更好地保留种子内容补丁的形状进一步提升人类注意力相关性。特别地,使用一个边缘提取算子E从种子内容补丁中得到边缘补丁$P_{edge}=E(P_0)$。需要注意的是,在每个像素中$P_{edge}$是0-1范围内的值。最后简单得将边缘补丁$P_{edge}$转换成mask张量E,与T0有相同得维度。
使用张量E,就可以区分边缘与非边缘区域,并且限制添加到边缘区域的扰动。因此,注意力逃避损失$L_e$可以表示成如下形式:
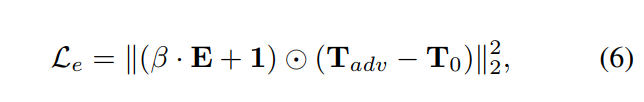
$\beta . E +1$是请权重张量,1是一个元素全为1的张量,它的维度与E一样,$ \odot $表示元素级别乘法。
引入smooth loss[13],该损失可以降低邻接像素之间的平方差(difference square),从而进一步提升伪装的自然性。对于一张对抗图像$I_{adv}$,平滑损失可以表示成
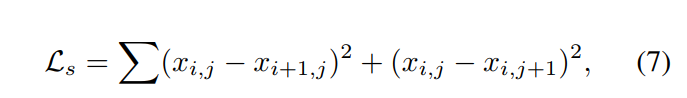
其中$x_{i,j}$是$I_{adv}$中坐标(i,j)处的像素值。
综上所述,在这个例子下生成的伪装在像素和感知层级与场景上下文就存在视觉相关。
优化过程概览
总的来说,我们通过联合优化模型注意力损失$L_d$、人类注意力逃避损失$L_e$和平衡损失$L_s$。
具体的,我们首先将目标网络的注意力从显著物体分散到无意义部分;然后通过增强与场景上下文强烈感知相关性来逃避人类特定的注意力机制。因此,通过最小化下面的公式生成迁移性和视觉更自然的对抗性伪装。
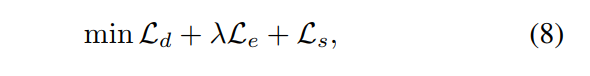
其中λ是控制损失项Le的贡献。为了平衡攻击能力和外观的自然性,1e-5的权重用于攻击分类任务,1e-3的权重用于检测任务,根据实验结果将β设为8。
双抑制注意力攻击算法如下:

实验
实验设置
虚拟环境:CARLA[10]作为3D虚拟模拟环境。可以模拟城市布局,建筑和车辆生成一个近似真实世界的数字世界。
评价指标:分类任务用准确率(Accuracy);检测任务用$P@05$[48],同时反映了IoU和精确度信息。
比较方法:UPC[19],CAMOU[48],MeshAdv[44]。为了更好的进行分析,使用了不同的方式来实现MeshAdv,使用ResNet-50作为分类的基础模型,YOLO-V4用于检测。
目标模型:分类任务攻击了Inception-V3,VGG-19,ResNet-152,DenseNet。检测任务使用了YOLO-V5[35],SSD[32],FASTER R-CNN[36]和MASK R-CNN[14]。所有模型分布是ImageNet和COCO上的预训练模型。
实现细节:λ设为$10^{-5}$和$5 \times 10 ^{-3}$分布对于分类任务和检测任务,β设置为8。使用lr=0.01,weight decay $10^{-4}$参数的adam,最大为5epoch。训练阶段,种子内容补丁(一个笑脸)作为3D物体的外观。物理世界攻击使用了黑盒攻击设置。Tesla V100 16GB。
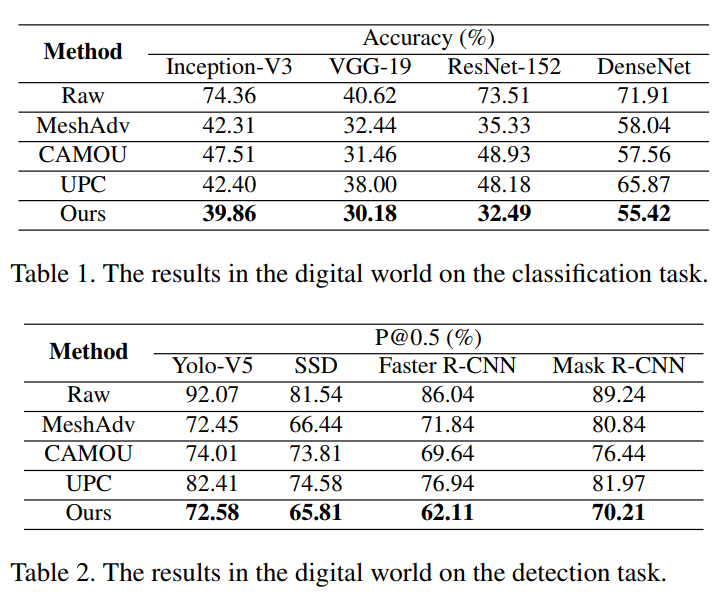
数字世界攻击
介绍了实验设置:实验环境设置(模拟环境中选择155个点放置车辆,并在不同环境设置下使用虚拟相机在每个点捕获100张图像)。总数据集,训练时候使用的backbone模型:ResNet-50(分类)和YOLO-V4(检测),其实也是相当于攻击了白盒模型,然后使用针对白盒模型生成的对抗扰动去攻击未知模型(黑盒攻击)。
结论:
- 生成的对抗性伪装在分类和检测下均能达到最好的性能(针对ResNet-152可以下降40.02%,针对Faster R-CNN可以下降23.93%)。
- 在检测任务中,UPC工作相对来说比其他baseline更差。推测原因可能是UPC主要针对物理攻击设计的,所以在数字攻击时能力下降。相反,DAS攻击利用了内在特征,在数字世界仍然可以取得很好的攻击能力。
- SSD显示了较其他backbone方法更好的鲁棒性(更低的accuracy下降)。可能原因是SSD中的一些模块不那么容易被对抗攻击(解释很牵强?),这提供了提高模型的鲁棒性。(作者的未来工作)
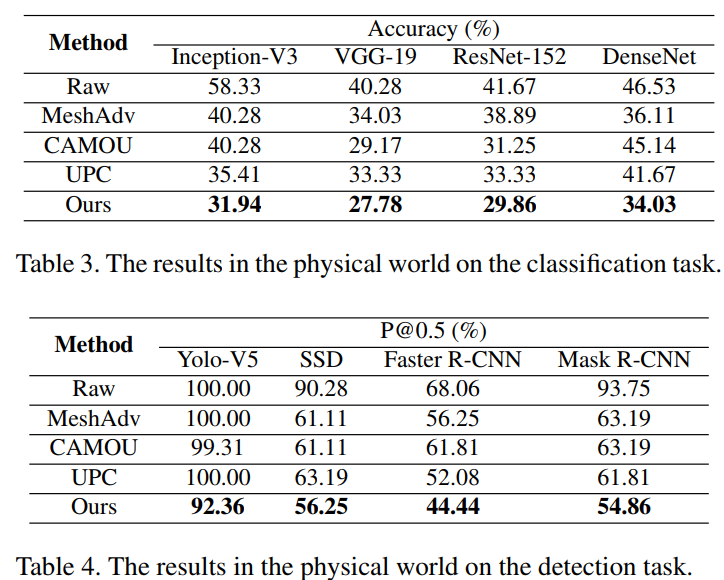
物理世界攻击
由于资金和条件的限制,作者使用HP彩色打印机(LaserJet Pro MFP M281fdw)打印了对抗性伪装并且将它们张贴在不同背景下的玩具车上来模拟真实的车辆绘制。(对抗性伪装的大小对识别有影响吗?)。介绍实验设置。
总结,实验结果证明了在物理世界中对抗性伪装具有强大的迁移攻击能力。
模型注意力分析
本部分,作者对通过定量和定性研究对模型注意力进行了详细的分析,以此验证DAS对分散模型注意力的有效性。
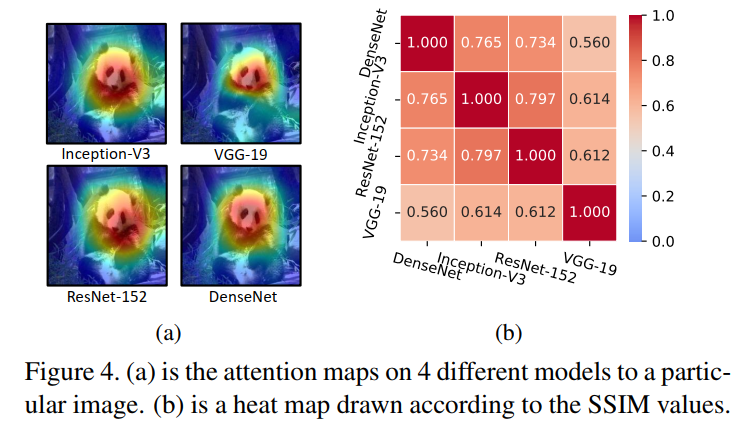
首先,通过可视化不同模型对相同图像的注意力区域进行定性研究。如下图所示,不同DNNs在相同图像上显示了相似的注意力模式。换句话说,不同模型会将他们的注意力聚焦在相同的未知,意味着注意力在不同的模型间是共享的,并且可以认为是模型不可认知的特征。
然后,通过计算SSIM来进行定量分析。特别的,生成了在相同模型上特定图像的注意力图,并且计算了不同模型的每对注意力图。如上图所示。
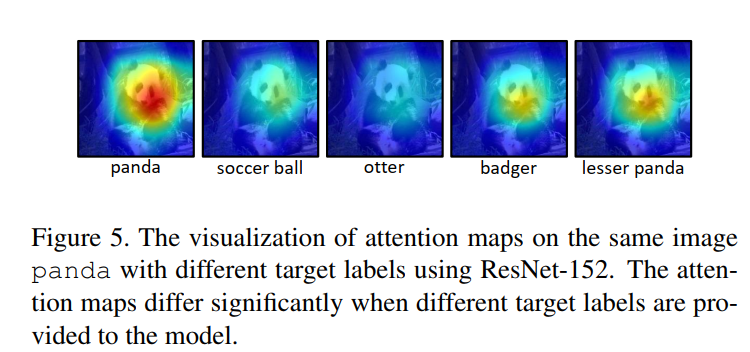
此外,还进一步可视化了通过改变模型预测(类别)的视觉注意力图。如下图所示。从图中可以看出,注意力图已经被从显著物体上分散开并且在整张图上显示出更加稀疏的特征。

总结
- 不同DNN对特定图像中的同一类别显示出相似的注意力模式。
- 可以同归分散DNN的注意力来实现对DNN的对抗性攻击。
人类感知研究
使用不同的baseline方法来扰动3D车辆,然后得到对抗性纹理。然后使用这些伪装得到渲染图像来进行感知性研究。
- 感知:参与者被要求将上述方法生成的每种伪装分配到 8 个类中的一个(真实类,6 个类与真实类,“我不知道它是什么”)。 至于CAMOU,由于缺乏语义信息,我们不考虑将其用于识别任务;
- 自然性:参与者被要求对伪装的自然性打分,分数在1到10之间。收集了106个参与者的反映。
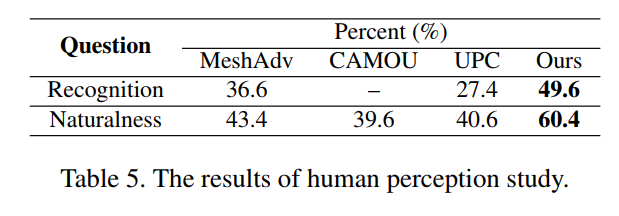
如下表所示,49.6%的参与者将作者的伪装认为是真实的,远高于其他方法。自然性任务中,高于60.4%的参与者相信作者生成的伪装看起来更加自然,得出的结论是作者的对抗性伪装看起来更加自然且与人类感知更加一致性。
消融实验
研究了两个损失项不同的贡献。由于平滑损失已经在[13]中得到了充分的研究,故将其固定。
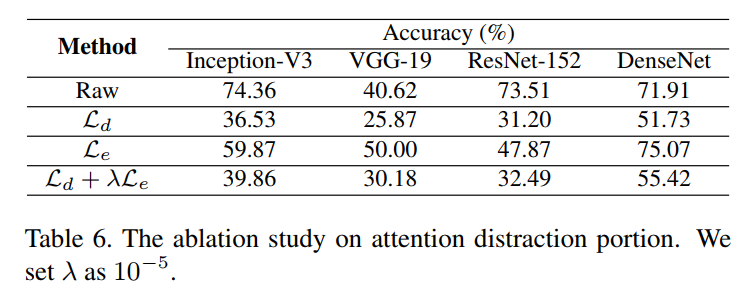
不同损失项的效果。不同损失项扮演者不同的角色,故而研究不同损失项的效果。作者认为模型注意力分散损失Ld主要扮演着提供可转移性的能力,人类注意力逃避损失提供了自然的外观。因此,分别使用了以下三种不同的策略来优化伪装(固定Ls,平滑损失):Ld,Le和Ld+λLe。实验结果如下表所示。
超参数λ的效果:作者认为超参数控制了场景上下文与强语义相关性的水平。在ResNet-50模型上使用ACC和SSIM来验证其有效性。结果如下图所示
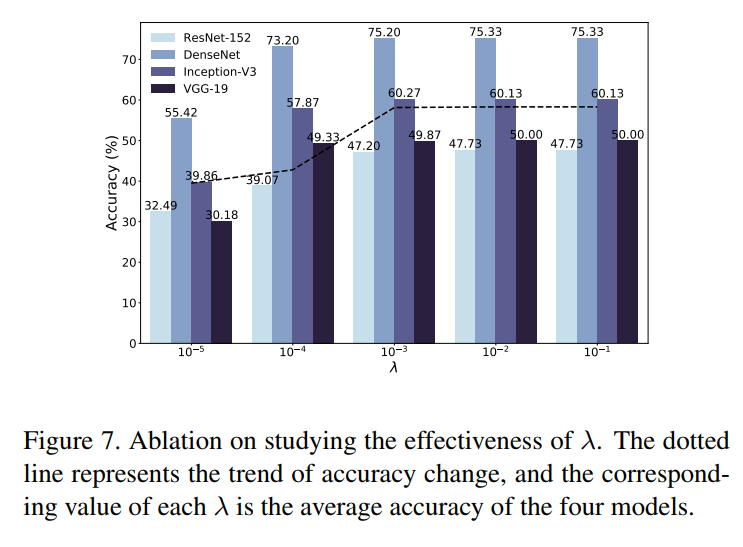
根据实验结果显示,λ平衡了accuracy和ssim值变大,这意味着更低的攻击能力和更好的外观。最终,SSIM达到了其上界,导致了失去额外的攻击能力。
结论
在本文中,我们提出了双重注意力抑制 (DAS) 攻击,通过抑制模型和人类注意力来在物理世界中生成对抗性伪装。为了提高对抗性伪装的可转移性,我们通过将模型共享的相似注意力从目标区域转移到非目标区域来抑制模型注意力。由于我们生成的伪装捕获了模型不可知结构,因此它可以在不同模型之间转移。为了产生视觉上更自然的伪装,我们通过逃避人类特定的自下而上的注意力来抑制人类的注意力。通过保留与场景上下文具有强语义关联的种子内容补丁的形状,生成的伪装可以与人类感知高度相关,这对人类的注意力更加自然和不怀疑。我们在黑盒设置下的数字和物理世界中对分类和检测任务进行了广泛的实验,我们的 DAS 优于最先进的基线。
未来,我们有兴趣在现实世界场景中使用真实车辆研究我们的对抗伪装的攻击能力。 使用投影或 3D 打印,我们可以简单地在现实世界的车辆上绘制我们的伪装。 此外,我们还想研究我们生成的伪装在提高模型对不同噪声的鲁棒性方面的有效性。
词汇
- camouflages 迷彩、伪装
- distracting 分散注意力
- a long line of 一长串
- confine 受限的
- conjecture 推测
- qualitative and quantitative 定性和定量