【对抗样本(二)】Adversarial Patch
导语:这是谷歌在2017年NIPS上发表的一篇对抗性补丁的论文
arXiv: https://arxiv.org/abs/1712.09665
github:
摘要
作者提出了一种方法来创建真实世界中通用的、鲁棒的、目标对抗图像补丁。补丁是通用的原因在于他们可以被用于攻击任何场景;鲁棒是因为他们在各种各样的变换下仍有效果;目标是因为他们可以误导某个分类器输出任意目标类别。这些对抗补丁可打印,并添加到任意场景、拍照并提供给图像分类器;甚至当补丁很小时,他们也能误导分类器忽略场景中的其他项(目标)并报道一个被选择的目标类别。
介绍

深度学习系统很容易受到对抗样本的影响,仔细选择在不改变人类视觉基础上,可以使网络改变输出的输入。这些对抗样本最常见仅修改少量修改每个像素,可以使用一些优化策略来找到这些样本,如L-BFGS,FGSM,DeepFool, PGD,和最近提出的为解决离散输入的LS-PGA。其他攻击方法寻求修改图像中少量的像素值(基于雅可比的显著图),或者在图像固定位置的一个小的补丁。
对抗样本已被证明可以推广到现实世界。Kurakin等人【7】证明当打印出来时,一个对抗性构建的图像将会继续对分类器具有攻击性,甚至在不同的光照和角度。最近,Athalye等人【3】证明可以3d打印的对抗性物体,可以在不同角度和尺度上被网络错分类。他们的对抗性对象被设计成对正常对象的轻微扰动(e.g. 乌龟被对抗性扰动,然后被分类成步枪)。其他工作【13】展示了一种通过构造对抗性眼镜来欺骗面部识别软件。这些眼镜的目标在于它们可以被构造成模仿任何人,但它们是为攻击者的脸定制的,并且在设计时考虑了固定的方向。甚至最近,Evtimov等人【4】证明很多方法构建的停止标志被模型误分类,要么通过打印出一个大的像停止标志的海报,要么通过在停止标志上贴上一些不同的贴纸。在防御方面,已经有大量工作将图像模型的对抗鲁棒性提高到输入的较小的Lp扰动。
就如上面可见,大量前期的工作聚焦在攻击和防御对输入的既小又不可感知性的改变。在这个工作中我们探索攻击者不再将他们限制在不可感知性的改变的可能性。我们构建了一种攻击,这种攻击不再尝试将现存的目标轻微的转换成其他目标。相反的,这种攻击会生成一个与图像无关的补丁,这个对神经网络非常重要。然后可以将该补丁放置在分类器视野内的任何位置,并且误导分类器输出一个目标类。由于这个补丁是场景独立的,这就允许攻击者创建不需要光照条件、相机角度、被攻击分类器的类型,甚至场景中其他项的先验知识下的一种物理攻击。
这种攻击非常重要,因为攻击者在构建攻击时,不需要了解他们要攻击的图像。在生成一个对抗性补丁后,补丁可以通过跨过互联网广泛的传播,可以被其他攻击者打印出来并且使用。此外,由于攻击使用了大规模扰动,现有的聚焦于防御小的扰动的防御技术可能对像这样的大规模扰动不鲁棒(无效)。实事实上,最近的工作表明,在MNIST数据集上最先进的对抗训练模型,比起通过使用不同的距离度量【14】搜索附近的对抗样本,或者在背景中使用更大的扰动【1】的对抗样本,更容易受到更大的扰动的影响。
方法
| 传统寻找对抗样本的策略:可以表示成如下形式:给定一些分类器$P[y | x]$, 一些输入$ x \in R^n$,一些目标类$\hat{y}$和一个最大扰动$\epsilon$ ,我们想要找到输入$\hat{x}$,最大化对数$P[\hat{y} | \hat{x}]$,且满足约束条件$ | x-\hat{x} | _\infin \le \epsilon$。当$P[y | x]$是由一个神经网络进行参数化,攻击者可以访问模型并且能够在x上执行迭代的梯度来找到合适的$\hat{x}$。这种策略可以生成很好的伪装攻击,但是需要修改目标图像。 |
作者的策略:相反,我们通过使用补丁完全替换图像中的一部分来创建攻击。我们掩盖了我们的补丁以允许它有任意形状,然后再各种图像上进行训练,在每张图像的补丁上应用随机变换、缩放和旋转。特别的,给定图像$x\in R^{w\times h \times c}$,补丁p,补丁位置$l$,补丁变换$t$(旋转或缩放),我们定义了补丁应用操作A(p, x, l, t),首先对补丁p进行变换t,然后将转换后的补丁p贴在图像x的l位置处。为了得到训练好的补丁$\hat{p}$,我们使用了多种Expectation over Transformation(EOT)开框架【3】。特别的,通过最优化下述目标函数可以得到训练好的补丁 \(\hat{p} = \textsf{arg} \max_p E_{x \sim X, t \sim T, l \sim L}[\textsf{log} Pr(\hat{y}|A(p,x,l,t))]\) 其中X是图像的训练集合,T是补丁的变换分布,L是图像的位置分布。注意这个期望是应用在图像上的,这鼓励训练好的补丁可以工作,而不用管它所处的背景。这与大多数先前在对抗扰动上的工作不同,事实上这种扰动是通用的它可以在任何背景下工作。通用扰动在【9】中提出,但是需要改变图像中的很多像素,结果也不能应用到物理世界。详细如图所示:

| 我们同样考虑了伪装补丁,这种补丁需要被强迫看起来像给定的初始图象一样。这里我们简单地添加一个约束$ | p-p_{orig} | \infin < \epsilon$到补丁对象上。这将逼迫最终补丁在开始补丁$p{orig}$的$L_\infin$的$\epsilon$的球形范围内。 |
我们相信这种攻击利用了图像分类任务的构建方式。然而图像可能包含很多个项目,仅有一个目标标签被认为是真实的,因此网络必须学会检测帧中最显著的项目。对抗性补丁通过产生比现实世界中的对象更显著的输入来利用此功能。因此,当攻击目标检测或图像分割模型时,我们希望目标烤面包机补丁可以分类成一个烤面包机,并且不会影响图像中的其他部分。
实验结果
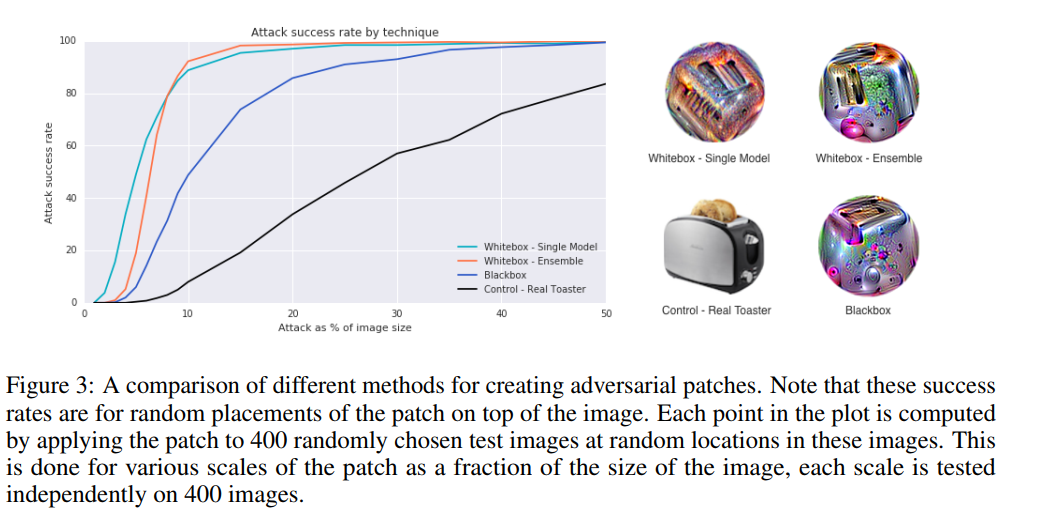
为了测试我们的攻击,我们比较了两种白盒攻击、一种黑盒攻击、和控制补丁的效果。白盒集成攻击在5个ImageNet模型上联合训练单个补丁:inceptionv3,resnet50,xception,vgg16和vgg19。随后我们通过平均所有5个模型的win rate来评估攻击。白盒但模型攻击一样,但是仅在单个模型上训练和验证。黑盒攻击在四个模型上联合训练一个单个补丁,然后再第五个模型上验证黑盒攻击(迁移性?),第五个模型在训练时是接触不到的。控制是一个烤面包机的图片。
在训练和验证阶段,补丁是经过缩放并且然后数字化地插入到一张随机ImageNet图像中的随机位置。图2显示了结果。
注意,在这个通用设置下(黑盒,目标类别,在所有图像上,位置和专函),可靠地欺骗模型所需要地补丁大小非常大,远超过哪些在白盒场景下单张图像和单个位置实现非目标攻击所需要的补丁大小。例如,最近Su等人【6】证明了在一张32 x 32像素大小的CIFAR-10数据集中修改1个像素(整张图像的0.1%)已经足够以非目标、非通用的白盒攻击欺骗大多数图像。然而,我们的攻击仍然远比天真地插入目标类别图像有效果,就如图2中将真实的烤面包机插入场景中获得了相对糟糕的性能。
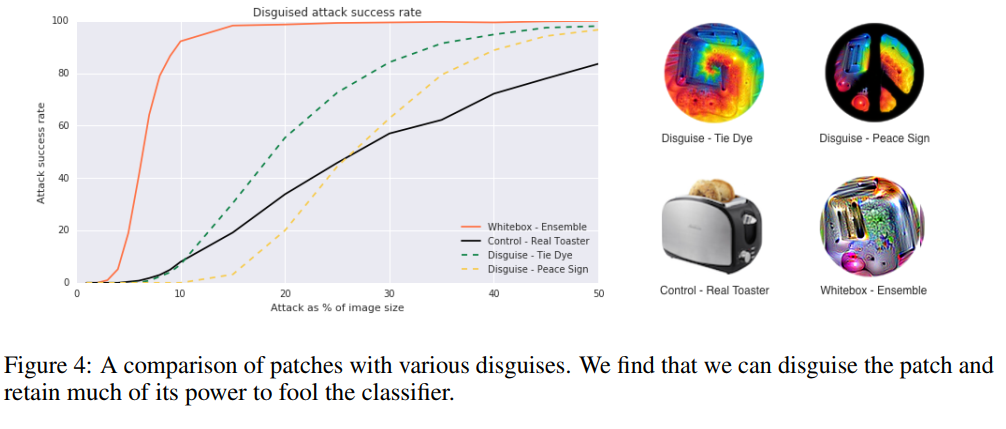
在图2中显示的任何攻击能够被伪装来减少对人类观察者的显著性。我们通过最小化它到tie-dye模式的L2距离和在训练过程中应用一小块标志掩膜来创建了伪装版本的补丁。这些实验结果在图3所示。
在我们最终的实验中,我们测试了我们攻击物理世界的可转移性。我们使用标志彩色打印机打印了生成的补丁,并将其应用到各种真实世界场景。实验结果如图1所示,攻击成功欺骗了分类器,甚至场景中还存在其他物体。攻击的视频证明可以观看链接https://youtu.be/i1sp4X57TL4。
我们同样在第三方Demitasse应用中测试了补丁在黑盒+物理世界场景下的效果,并且发现补丁有一定的迁移性,但是仅在补丁占图像的非常大一部分时才有这种效果。我们并没有为补丁进行的打印能力后攻击能力的优化【13】,这也许可以解释为什么在图3中不那么有效果,在不同模型上测试了黑盒,但不是在物理世界中。
结论
我们显示了我们可以生成一个通用的、鲁棒的、目标补丁,无论补丁的规模或位置如何,都可以欺骗分类器,并且不需要攻击场景中其他项的知识。我们的攻击在真实世界中仍然有效果,可以当作是无害的贴纸。这些结果表明可以离线创建攻击,然后广泛共享。
出于安全考虑【12,2,8】,现在有大量的工作研究防御对自然图像的小规模Lp扰动。该工作的一个动机之一就是潜在的恶意攻击可能不会考虑到在自然图像中生成小的或者不可感知的扰动,但是可能相反地选择向输入中添加大规模并且有效,但是显著的扰动,特别是当模型已经被设计成抵抗Lp扰动时。
很多ML模型运行时并不会要求人类对每个输入进行验证,因此恶意攻击可能不会考虑他们的攻击的不可感知性。即使人类可以发现这些补丁,他们可能不理解补丁的意图,相反可能会觉得是一种艺术形式。该工作显示了仅聚焦防御小范围扰动是不够的,大规模的,局部的扰动也能击败分类器。
词汇
- a wide variety of 各种各样的
- broadly vulnerable to 很容易受到。。。
- substanial work 大量工作
- innocuous sticker 无害贴纸
- with access to 可以访问
总结和感悟
总结:
- 一方面,与传统的、经典的对抗样本定义不同,作者从真实世界的角度出发,考虑到对抗样本的不可感知性在实际恶意攻击场景中并不重要,因为诸如人工智能监控设备在监控时,无法做到始终有人在监视器前进行监视。为了实现效率更高的攻击,可以使用规模更大的扰动,但又不同于直接使用目标图像进行替换原始图像的方式。
- 另一方面, 现在很多对对抗样本防御方法仅能防御在Lp距离范围内搜索的对抗样本,对于大规模扰动的对抗样本仍然很脆弱,这也给对抗样本防御方法提了个醒:要考虑对抗样本是由大规模对抗性补丁构成的情况。
感悟
虽然作者说真实世界中牺牲不可感知性的大规模对抗性补丁构建的高效攻击成功率是更为实际的恶意攻击。然而细想下来,对于一些无关紧要的应用,比如说行人监控或者常用的一些AI应用,作者的思路并没有错。但对于一些对安全性比较高的场景或区域时,尽管采取了人工智能监控的设备,但是仍然会真人监控,这样如果发现有人手持某些特殊的贴纸或物件而没有被监控标记出来,那么其实更容易被当作是可疑人物。所以我认为同时考虑对抗样本的不可感知性仍然是有必要的。