人工智能的发展历史
导语:本博客摘自邱锡鹏的《神经网络与深度学习》,主要介绍人工智能中各种技术发展的历史,分别介绍人工智能、神经网络、机器学习、表示学习、深度学习
地址:https://nndl.github.io/
注:如有侵犯,请联系本人删除。
1 人工智能
1.1 基本概念
人工智能(Artifical Intelligence, AI)就是让机器具有人类的智能,这也是人们长期追求的目标。1950年,阿兰-图灵发表了一篇有着重要影响力的论文《Computing Machinery and Intelligence》,讨论了创造一种“智能机器”的可能性。提出了著名的图灵测试:一个人在不接触对方的情况下,通过一种特殊的方式和对方进行一系列的问答。
1956年的达特茅斯会议上,“人工智能”被提出并作为本研究领域的名词。同时,人工智能研究的使命也得以确定。John McCarthy提出了人工智能的定义:人工智能就是让机器的行为看起来就像是人所表现出的智能行为一样。
目前,人工智能的主要领域大体上可以分为以下几方面:
(1)感知:模拟人的感知能力,对外部刺激信息(视觉和语音等)进行感知和加工。主要研究领域包括语音信息处理和计算机视觉等。
(2)学习: 模拟人的学习能力,主要研究如何从样例或从与环境的交互中进行学习。主要研究领域包括监督学习、无监督学习和强化学习等。
(3)认知:模拟人的认识能力,主要研究领域包括知识表示、自然语言处理、推理、规划、决策等。
1.2 人工智能的发展历史
人工智能从诞生至今,经历了一次又一次的繁荣与低谷,其发展历程大体上可以分为“推理期”,“知识期”和“学习器”。【周志华,西瓜书】。
人工智能低谷,也叫人工智能冬天,指人工智能史上研究资金及学术界研究兴趣都大幅度减少的时期。人工智能领域经过好几次低谷期。每次狂热高潮之后,紧接着是失望、批评以及研究资金断绝,然后在几十年后又重燃研究兴趣。1974-1980年及1987-1993年是两个主要的低谷时期,其他还有几个较小的低谷。
第一阶段:推理期
1956年达特茅斯会议之后,研究者对人工智能的热情高涨,之后的十几年是人工智能的黄金时期。大部分早期研究者都通过人类的经验,基于逻辑或者事实归纳出来一些规则,然后通过编写程序来让计算机完成一个任务。但是随着研究的深入,研究者意识到这些推理规则过于简单,对项目难度评估不足,原来的乐观预期受到严重打击。人工智能的研究开始陷入低谷,很多人工智能项目的研究经费也被削减。
第二阶段:知识期
到了20世纪70年代,研究者意识到知识对于人工智能系统的重要性。特别是对于一些复杂的任务,需要专家来构建知识库。在这一时期,出现了各种各样的专家系统(Expert System),并在特定的专业领域取得了很多成果。专家系统可以简单理解为“知识库+推理机”,是一类具有专门知识和经验和计算机智能程序系统。专家系统一般采用知识表示和知识推理等技术来完成通常由领域专家才能解决的复杂问题,因此专家系统也被称为基于知识的系统。
一个专家系统必须具备三要素:1)领域专家知识; 2) 模拟专家思维; 3)达到专家级的水平。
在这一时期,Prolog(Programming in Logic)语言是主要的开发工具,用来建造专家系统、智能知识库以及处理自然语言理解等。
第三阶段:学习期
研究者开始将研究重点转向让计算机从数据中自己学习。“学习”本身也是一种智能行为。从人工智能的萌芽时期开始,就有一些研究者尝试让机器来学习自动学习,即机器学习(Machine Learning, ML)。机器学习的主要目的是设计和分析一些学习算法,让计算机可以从数据(经验)中自动分析并获得规律,之后利用学习到的规律对未知数据进行预测,从而帮助人们完成一些特定任务,提高开发效率。在人工智能领域,机器学习从一开始就是一个重要的研究方向。但到1980年后,机器学习因其在很多领域的出色表现,才逐渐称为了热门学科。
机器学习的研究内容也十分广泛,涉及线性代数、概率论、统计学、数学优化、计算复杂性等多门学科。
在发展了60多年后,人工智能虽然可以在某些方面超越人类,但想让机器真正通过图灵测试,具备真正意义上的人类智能,这个目标看起来仍然遥遥无期。
1.3 人工智能的流派
尽管人工智能的流派非常多,但主流的方法大体上可以归结为以下两种:
(1)符号主义(Symbolism):又称逻辑主义、心理学派或计算机学派,是指通过分析人类智能的功能,然后用计算机来实现这些功能的一类方法。符号主义有两个基本假设:a)信息可以用符号来表示;b)符号可以通过显示的规则(比如逻辑运算)来操作。人类的认知过程可以看作符号操作过程。在人工智能的推理期和知识期,符号主义的方法比较盛行,并取得了大量的成果。
(2)连接主义(Connectionism),又称仿生学派或生理学派,是认知科学领域中的一类信息处理的方法和理论。在认知科学领域,人类的认知过程可以看作一种信息处理过程。连接主义认为人类的认知过程是由大量简单神经元构成的神经网络中的信息处理过程,而不是符号运算。因此,连接主义模型的主要结构是由大量简单的信息处理单元组合成的互联网络,具有非线性、分布式、并行化、局部性计算以及自适应等特性。
符号主义方法的一个优点是可解释性,而这也正是连接主义的弊端、深度学习的主要模型神经网络就是一种连接主义模型,随着深度学习的发展,越来越多的研究者开始关注如何融合符号主义和连接主义,建立一种高效并且具有可解释性的模型。
2 神经网络
导语:神经网络的发展大致经过了五个阶段,启蒙时期/模型提出期(1943-1969),低潮时期/冰河期(1969-1983),复兴时期/反向传播算法引起的复兴期(1983-1995),流行度降低期(1995-2006),深度学习的崛起(从2006年开始至今)
第一阶段:启蒙时期/模型提出期(1943-1969)
该阶段是神经网络发展的第一个高潮期。在此期间,科学家们提出了许多神经元模型和学习规则。
-
1943年,心理学家Warren McCulloch【沃伦·麦卡洛克】和数学家Walter Pitts【沃尔特·皮茨】最早提出了一种基于简单逻辑运算的人工神经网络,这种神经网络模型称为MP模型,至此开启了人工神经网络研究的序幕。
另一种表述:由神经科学家麦卡洛克(Warren McCulloch)和数学家皮茨(Walter Pitts)在《数学生物物理学公告》上发表论文《神经活动中内在思想的逻辑演算》(A logical Calculus of the Ideas Immanent in Nervous Activity)。建立了神经网络和数学模型,称为MCP模型。该模型其实是按照生物神经元的结构和工作原理构造出来的一个抽象和简化了的模型,也就诞生了所谓的“模拟大脑”,人工神经网络的大门由此开启。
-
1948年,Alan Turing【艾伦·图灵】提出了一种“B型图灵机”,该图灵机基于Hebbian法则来进行学习。
-
1951年,McCulloch【麦卡洛克】和Pitts【皮茨】的学生Marvin Minsky【马文·明斯基】建造了第一台神经网络机SNARC(Minsky是人工智能领域最重要的领导者和创新者之一,MIT人工智能实验室的创始人之一,因其在人工智能领域的贡献,于1969年获得图灵奖)。
-
1958年,Rosenblatt【罗森布拉特】提出了一种可以模拟人类感知能力的神经网络模型,称为感知机(Perceptron),并提出了一种接近人类学习过程(迭代、试错)的学习算法。
另一种表述:计算科学家罗森布拉特提出了两层神经元组成的神经网络,称之为“感知器(Perceptrons)”。第一次将MCP用于机器学习(machine learning)分类(classification)。“感知器”算法使用MCP模型对输入的多维数据进行了二分类,且能够使用梯度下降法从训练样本中自动学习更新权值。1962年,该方法被证明为能够收敛,理论与实践效果引起了第一次神经网络的浪潮。
在这一时期,神经网络以其独特的网络结构和处理信息的方法,在许多实际应用领域(自动控制、模式识别等)中取得了显著的成效。
第二阶段:低潮时期/冰河期(1969-1983)
该阶段是神经网络发展的第一个低谷期,在此期间,神经网络的研究处于常年停滞及低潮状态。
-
1969年,Marvin Minsky【马文·明斯基】出版《感知器》一书,指出了神经网络的两个关键缺陷:
- 一是感知器无法处理“异或”回路问题
- 二是当时的计算机无法支持处理大型神经网络所需要的计算能力
另一种表述:1969年,美国数学家及人工智能先驱Marvin Minsky【马文·明斯基】在其著作《感知器》中证明了感知器本质上是一种线性模型(linear model),只能处理线性分类问题,就连最简单的XOR(异或)问题都无法正确分类。这等于直接宣判了感知器的死刑,神经网络的研究也陷入了将近20年的停滞。
这些论断使得人们对以感知器为代表的神经网络产生质疑,并导致神经网络的研究进入了十多年的“冰河期”
- 但是在这时期,依然有不少学者提出了很多有用的模型或算法。1974年,哈佛大学的Paul Werbos【保罗·韦伯斯】发明反向传播算法(BackPropaggation, BP),但是当时受到应有的重视。
- 1980年,福岛邦彦提出了一种带卷积和子采样操作的多层神经网络:新知机(Neocognitron)。新知机的提出是受到了动物初级视觉皮层简单细胞和复杂细胞的感受野的启发。但是新知机没有采用反向传播算法,而是采用了无监督学习的方式来训练,因此也没有引起足够的重视。
第三阶段:复兴时期/反向传播算法引起的复兴期(1983-1995)
另一种表述:由神经网络之父Geoffrey Hinton在1986年发明了适用于多层感知器(MLP)的BP算法,并采用了Sigmoid进行非线性映射,有效解决了非线性分类和学习问题。该方法引起了神经网络的第二次热潮。
该阶段是神经网络发展的第二个高潮期。这个时期中,方向传播算法重新激发了人们对神经网络的兴趣。
- 1983年,物理学家John Hopfield【约翰·霍普菲尔德】提出了一种用于联想记忆(Associative Memory)的神经网络,称为Hopfield网络。该网络在旅行商问题上取得了当时最好结果,并引起了轰动。
- 1984年,Geoffrey Hinton【杰弗里·辛顿】提出了一种随机化版本的Hopfield网络,即玻尔兹曼机(Boltzmann Machine)。
- 真正引起神经网络第二次研究高潮的是反向传播算法。20世纪80年代,一种连接主义模型开始流行,即分布式并行处理(Parallel Distributed Processing, PDP)模型【McClelland et al., 1986,麦克莱兰德】。反向传播算法也逐渐成为PDP模型的主要学习算法。这时,神经网络才又开始引起人们的注意,并重新成为新的研究问题。
- 随后,【LeCun et al., 1989】将反向传播算法引入了卷积神经网络(LeNet),并在手写体数字识别上取得了很大的成功。反向传播算法是迄今最为成功的神经网络学习算法。目前在深度学习中主要使用的自动微分可以看作反向传播算法的一种扩展。
- 然而,梯度消失问题(vanishing Gradient Problem)阻碍神经网络的进一步发展,特别是循环神经网络。为解决这一问题,【Schmidhuber,施密德胡伯】采用两步来训练一个多层的循环神经网络:1)通过无监督学习的方法来逐层训练每一层循环神经网络,即预测下一个输入;2)通过反向传播算法进行精调。
第四阶段:流行度降低期(1995-2006)
1991年BP算法被指出存在梯度消失问题,也就是说误差梯度在后向传播的过程中,后层梯度以乘性方式叠加到前层,由于Sigmoid函数的饱和特性,后层梯度本来就小,误差梯度传到前层时几乎为0,因此无法对前层进行有效的学习,该问题直接阻碍了深度学习的进一步发展。
此外90年代中期,支持向量机算法诞生(SVM算法)等各种浅层机器学习模型被提出,SVM也是一种有监督的学习模型,应用于模式识别、分类以及回归分析等。支持向量机以统计学为基础,和神经网络有明显的差异,支持向量机算法的提出再次阻碍了深度学习的发展。
在此期间,支持向量机和其他更简单的方法(例如线性分类器)在机器学习领域的流行度逐渐超过了神经网络。
虽然神经网络可以很容易地增加层数、神经元数量,从而构建复杂的网络,但其计算复杂度也会随之增长。当时的计算机性能和数据规模不足以支持训练大规模神经网络。在20世纪90年代中期,统计学习理论和以支持向量机为代表的机器学习模型开始兴起。相比之下,神经网络的理论基础不清晰、优化困难、可解释性差等缺点更加凸显,因此神经网络的研究又一次陷入低潮。
第五阶段:深度学习的崛起(从2006年开始至今)
2006年,加拿大多伦多大学教授、机器学习领域泰斗、神经网络之父—Geoffrey Hinton和他的学生Rushlan Salakhutdinov在顶尖学术刊物《科学》上发表了一篇文章,该文章提出了深度网络训练中梯度消失问题的解决方案:无监督预训练对权值进行初始化+有监督训练微调。斯坦福大学、纽约大学、加拿大蒙特利尔大学等成为研究深度学习的重镇,至此开启了深度学习在学术界和工业界的浪潮。
2011年,ReLU激活函数被提出,该激活函数能够有效的抑制梯度消失问题。
- 2011年以来,微软首次将DL应用在语音识别上,取得了重大突破。
- 2012年,DNN技术在图像识别领域取得惊人的效果。
爆发期2012-2017(在该分类下)
2012年,Hinton课题组为了证明深度学习的潜力,首次参加了ImageNet图像识别比赛,其通过构建的CNN网络AlexNet一举夺得冠军,且碾压第二名(SVM方法)的分类性能。也正式由于该比赛,CNN吸引了众多研究者的注意。
AlexNet的创新点在于:
- 首次采用ReLU激活函数,极大增大收敛速度且从根本上解决了梯度消失问题。
- 由于ReLU方法可以很好抑制梯度消失问题,AlexNet抛弃了“预训练+微调”的方法,完全采用有监督训练。也正因为如此,DL的主流学习方法也因此变为了纯粹的有监督学习。
- 扩展了LeNet5结构,添加了Dropout层减少过拟合,LNR层泛化层增强泛化能力/减少过拟合。
- 第一次使用GPU加速模型计算。
在这一时期研究者逐渐掌握了训练深层神经网络的方法,使得神经网络重新崛起。
- 【Hinton et al. 2006】通过逐层预训练来学习一个深度信念网络,并将其权重作为一个多层前馈神经网络的初始化权重,再用反向传播来进行微调。这种“预训练+精调”的方式可以有效地解决深度神经网络难以训练的问题。
- 随着深度神经网络在语音识别【Hinton et al., 2012】和图像分类【Krizhevsky et al., 2012,克里热夫斯基】等任务上的巨大成功,以神经网络为基础的深度学习迅速崛起。近年来,随着大规模并行计算以及GPU设备的普及,计算的计算能力得以大幅度提高。此外,可供机器学习的数据规模也越来越大。在强大的计算能力和海量的数据规模支持下,计算机已经可以端到端地训练一个大规模神经网络,不再需要借助预训练的方式。各大科技公司都投入巨资研究深度学习,神经网络迎来第三次高潮。
3 机器学习
机器学习是指从有限的观测数据中学习(或“猜测”)出具有一般性的规律,并利用这些规律对未知数据进行预测的方法。机器学习是人工智能是一个重要分支,并逐渐成为人工智能发展的关键因素。
在实际任务中使用机器学习模型一般会包含以下几个步骤:
(1)数据预处理:经过数据的预处理,如去除噪声等。比如在文本分类中,去除停用词等。
(2)特征提取:从原始数据中提取一些有效的特征。比如在图像分类中,提取边缘、尺度不变特征变换(SIFT)特征等。
(3)特征转换:对特征进行一定的加工,比如降维和升维。降维包括特征抽取(Feature Extraction)和特征选择(Feature Selection)两种途径。常用的特征转换方法有主成分分析(Principal Components Analysis, PCA)、线性判别分析(Linear Discriminant Analysis, LDA)等
(4)预测:机器学习的核心部分,学习一个函数并进行预测。
上述流程中,每步特征处理以及预测一般都是分开进行的。传统的机器学习模型主要关注最后一步,即构建预测函数。但在实际操作过程中,不同预测模型的性能相差不多,而前三步中的特征处理对最终系统的准确性有着十分关键的作用。特征处理一般都需要人工干预完成,利用人类的经验来选取好的特征,并最终提高机器学习系统的性能。因此,很多的机器学习问题变成了特征工程(Feature Engineering)问题,开发一个机器学习系统的主要工作量都消耗在了数据预处理、特征提取以及特征转换上。
4 表示学习
为了提高机器学习系统的准确率,需要将输入信息转换为有效的特征,或者更一般性地成为表示(Representation)。如果有一种算法可以自动地学习出有效地特征,并提高最终机器学习模型的性能,那么这种学习就可以叫作表示学习(Representation Learning)。
语义鸿沟:表示学习的关键是解决语义鸿沟(Semantic Gap)问题。语义鸿沟问题是指输入数据的底层特征和高层语义信息之间的不一致性和差异性。
表示学习中,有两个核心问题:一是“什么是一个好的表示”;二是“如何学到好的表示”。
4.1 局部表示和分布式表示
一般而言,一个好的表示具有以下几个优点:
- 一个好的表示应该具有很强的表示能力,即同样大小对的向量可以表示更多信息
- 一个好的表示应该使后续的学习任务变得简单,即需要包含更高层的语义信息。
- 一个好的表示应该具有一般性,是任务或领域独立的。虽然目前的大部分表示学习方法还是基于某个任务来学习,但我们期望其学的表示可以比较容易地迁移到其他任务上。
在机器学习中,我们经常使用两种方式来表示特征:局部表示(Local Representation)和分布式表示(Distributed Representation)
以颜色为例,一种表示颜色的方法是以不同名字来命名不同的颜色,这种表示方式叫作局部表示,也称为离散表示或符号表示。局部表示通常可以表示为one-hot向量的形式。
局部表示有两个优点:
- 这种离散的表示方式具有很好的解释性,有利于人工归纳和总结特征,并通过特征组合进行高效的特征工程;
- 通过多种特征组合得到的表示向量通常是稀疏的二值向量,当用于线性模型时计算效率非常高,但局部表示有两个不足之处;
- one-hot向量的维度很高,且不能扩展,如果有一种新的颜色,我们就需要增加一维来表示
- 不同颜色之间的相似度都为0,即无知道“红色”和“中国红”的相似度要高于“红色”和“黑色”的相似度。
分布式表示
分布式表示具有丰富的相似性空间,语义上相似的概念(或输入)在距离上接近,这是纯粹的符号表示所缺少的特点。
另一种表示颜色的方法是用RGB值来表示颜色,不同颜色对应到RGB三维空间中一个点,这种表示方式叫作分布式表示分布式表示。分布式表示通常可以表示为低维的稠密向量(低维嵌入向量)。
和局部表示相比,分布式表示的表示能力要强很多,分布式表示的向量维度一般都比较低。
使用神经网络可将高维的局部表示空间映射到一个非常低维的分布式表示空间。在这个低维空间中,每个特征不再是坐标轴上的点,二是分散在整个低维空间中。在机器学习中,这个过程也成为嵌入(Embedding)。嵌入通常指将一个度量空间的一些对象映射到另一个低维的度量空间中,并尽可能保持不同对象之间的拓扑关系。比如自然语言处理中词的分布式表示,也经常叫作词嵌入。
4.2 表示学习
要学到一种好的高层语义表示(一般为分布式表示),通常需要从底层特征开始,经过多步非线性转换才能得到。深度结构的优点是可以增加特征的重用性,从而指数级地增加表示能力。因此,表示学习地关键是构建具有一定深度的多层次特征表示【Bengio】。
在传统的机器学习中,也有很多有关特征表示学习的方法,比如主成分分析、线性判别分析、独立成分分析等。但是,传统的特征学习一般是通过人为地涉及一些准则,然后根据这些准则来选取有效的特征。特征的学习是和最终预测模型的学习分开进行的,因此学习到的特征不一定可以提升最终模型的性能。
5 深度学习
5.1 相关概念
为了学习一种好的表示,需要构建具有一定“深度”的模型,并通过学习算法来让模型自动学习出好的特征表示(从底层特征,到中层特征,再到高层特征)
- 底层特征往往是泛化的、易于表达的,如纹理,颜色,边缘,棱角等。浅层(靠近输入)能提取到上述低层次特征
- 深层特征往往是复杂的、难以说明的,比如金色的头发、瓢虫的翅膀、缤纷的花儿等。深层(靠近输出)往往能提取到上述高层次特征。
,从而最终提升预测模型的准确率。所谓“深度”是指原始数据进行非线性特征转换的次数。如果把一个表示学习系统看作一个有向图结构,深度也可以看作从输入节点到输出节点所经过的最长路径的长度。
这样就需要一种学习方法从数据中学习一个“深度模型”,这就是深度学习。深度学习是机器学习的一个子问题,其主要目的是从数据中自动学习到有效的特征表示。
深度学习是将原始的数据特征通过多步的特征转换得到一种特征表示,并进一步输入到预测函数得到最终结果。和“浅层学习”不同,深度学习需要解决的关键问题是贡献度分配问题(Credit Assignment Problem, CAP)[Minsky,1961],即一个系统中不同的组件或其参数对最终系统输出结果的贡献影像。从某种意义上讲,深度学习可以看作一种强化学习(Reinforcement Learning, RL),每个内部组件并不能直接得到监督信息,需要通过整个模型的最终监督信息(奖励)得到,并且有一定的延时性。
目前,深度学习采用的模型主要是神经网络模型,其主要原因是神经网络模型可以使用误差反向传播算法,从而可以比较好地解决贡献匹配度分配问题。只要是超过一层的神经网络都会存在贡献度分配问题,因此可以将超过一层的神经网络都看作深度学习模型。随着深度学习的快速发展,模型深度也从早期的5-10层增加到目前的数百层。随着模型深度的不断增加,其特征表示的能力也越来越强,从而使后续的预测更加容易。
5.2 端到端学习
传统机器学习方法需要将一个任务的输入和输出之间人为地分割成很多子模块(或多个阶段),每个子模块分开学习。这种学习方式有两个问题
- 一是每一个模块都需要单独优化,并且其优化目标和任务总体目标并不能保证一致
- 二是错误传播,即前一步的错误会对后续的模型造成很大的影响。这样就增加了机器学习方法在实际应用中的难度。
端到端学习(End-to-End Learning),也称端到端训练,是指在学习过程中不进行分模块或分阶段训练,直接优化任务的总体目标。在端到端学习中,一般不需要明确地给出不同模块或阶段的功能,中间过程不需要人为干预。端到端学习的训练数据为“输入-输出”对的形式,无需提供其他额外信息。因此,端到端学习和深度学习一样,都是要解决贡献度分配分析。目前,大部分采用神经网络模型的深度学习也可以看作一种端到端的学习。
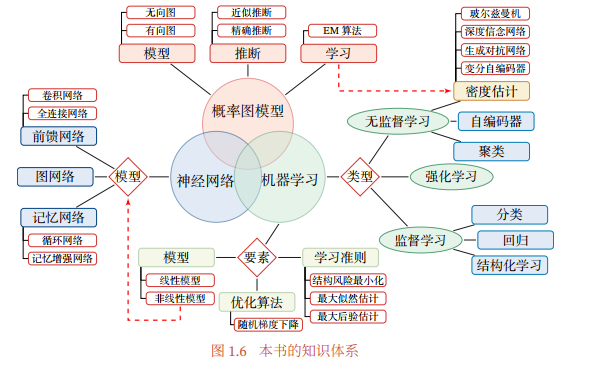
神经网络和深度学习的知识体系