【论文阅读(四)】Medical Transformer Gated Axial-Attention for Medical Image Segmentation
导语:本篇文章是在arXiv上的预印版, 将将transformer用于医学图像分割中的工作。作者通过在自注意模块中引入额外的控制机制来扩展现存的结构,提出的模型称为Gated Axial-Attention(Medical Transformer, MedT)。
arXiv:
github:https://github.com/jeya-mariajose/Medical-Transformer
摘要
在过去的十年,深度卷积神经网络被广泛地应用于图像分割并且取得了巨大的性能提升。然而,由于卷积结构固有的感应偏差,在图像中它们缺乏感应到长期依赖。最近提出的基于Transformer结构可以利用自主一机制编码长期依赖,并且学习具有高度表达力的表示。这是作者探究基于Transformer解决方案的原因,并且研究使用transformer结构实现医学图像分割任务的可行性。大多数现存的用于解决在计算机视觉任务的transformer网络结构需要大规模数据集才能恰当的训练。然而,与视觉应用的数据不同,对于医学图像的数据集样本数量相对较少,这使得很难有效地为医学应用训练一个transformer。为此,作者提出了一个Gated Axial-Attention模型,通过在自注意模块中引入额外的控制机制来拓展现存的结构。进一步地,为了有效地在医学图像中训练模型,提出了局部-全局训练策略(LoGo)进一步提升了性能。具体的,作者分别对整张图片和图像块进行处理来获得全局和局部特征。在三种不懂医学分割数据集上进行验证发现,与卷积网络和其他相关的Transformer结网络相比,提出的MedT方法可以获得最佳的性能。
背景
开发自动、准确和鲁棒的医学图像分割技术是医学成影的首要问题,是计算机辅助诊断和图像指导外科系统的关键。从医学扫描的器官和病灶的分割可以帮助临床医生做出准确的诊断,安排外科手术和提出治疗策略。医学分割的早期方法使用统计形状方法,基于轮廓图的方法和基于机器学习方法。随着ConvNets在计算机视觉的发展,ConvNets快速地被应用到医学图像分割任务。如U-NET,V-NET,3D U-NET, RES-UNET,DENSE-UNET,Y-UNET,U-NET++,KIU-NET,U-NET3++被提出用于解决不同医学图像模态中图像和体积分割任务。这些方法在很多困难数据集上获得了令人印象深刻地方法,证明了ConvNets可以有效地从医学扫描图像中学习到分割器官或病灶地判别性特征。
ConvNets是当前很多图像分割方法地基础构建块,如医学图像或计算机视觉任务。然而,ConvNets缺乏建模出现在图像中地长期依赖的能力。更精确地,在ConvNets中,每个卷积核倾向于图像中像素的邻近集合并迫使网络注意局部模式,而不是全局内容。已有工作研究使用图像金字塔、atrous卷积和注意力机制为ConvNets建模长期依赖。然而,可以注意到,由于大多数先前的方法并不专注于医学图像分割任务这一方面,因此对长期依赖性建模仍具有很大的改进空间。
作者通过可视化(如下图)早产儿的超声扫描并对扫描图像的脑室分割预测来说明为什么在医学图像中长期依赖的重要性。为网络提供有效的细分,网络应该有能力理解哪些像素相当于mask,哪些像素相当于背景。给定单个像素,网络需要理解该像素更接近mask还是背景。因为图像的背景是离散的,学习相当于背景的像素之间的长期依赖有助于防止网络讲像素错分类成mask,以减少假阳性。同样地,只要分割mask较大,学习相当于mask的长期依赖同样也有助于做出有效的预测。
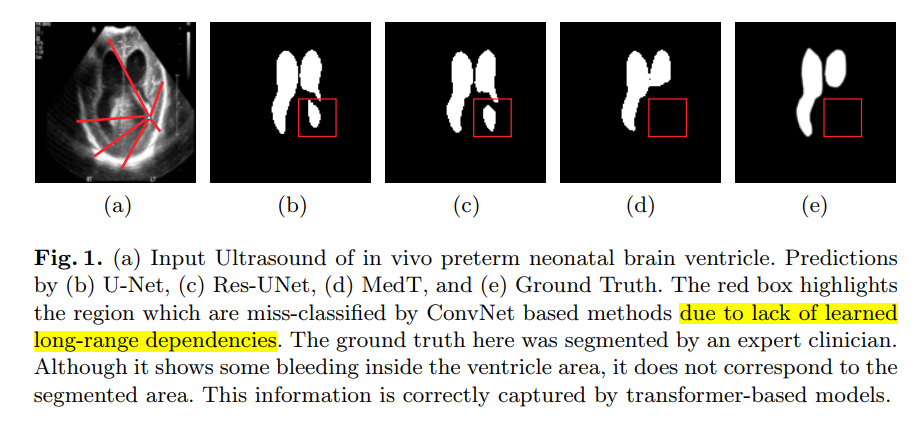
从图中可以看到,卷积网络错误地将背景分成了脑室,而提出地MedT没有犯这个错误。这是由于提出地方法学习了像素区域与背景的长期依赖。
最近如BERT和GPT的Transformer模型刷新了大多数NLP任务,如机器翻译,问答和文档分类。transformer成功的只要原因是它们有能力学习输入tokens之间的长期依赖。这可能是由于自注意机制可以找到输入中每个token与其他每个token之间的依赖。transformer在NLP中的热度,使得最近它们被应用到计算机视觉应用中。具体的,如ViT成功将带有位置嵌入的2D图像块用类似于语言翻译模型的输入序列的输入序列。在图像识别中,ViT取得了与在大规模数据预训练的卷积网络相似的性能。DeiT的提出展示了transformer如何应用到中等规模数据集。至于将transformer用于分割任务,Axial-Deeplab利用axial 注意力模块,该模块将2D自注意分解成1D自注意,并且引入位置敏感axial注意力设计来接近全景分割任务。Max-Deeplab利用一个mask transformer以端到端的方式来解全景分割任务。在分割Transformer(SETR)中,transformer被当作编码器,其输入一个图像块序列;ConvNet被用作解码器实现了一个强大的分割模型。
在医学图像分割中,基于transformer的模型尚待研究。最近的工作是使用注意力机制来提升性能。然而,这些网络的编解码器仍然将卷积层作为其主要构建模块。最近,TransUNET被提出,它使用一个基于transformer的编码器来处理图像块序列,带有跳跃连接的卷积解码器用于医学图像分割。TransUNet受到ViT的启发,它仍然依赖在其他大规模数据集上预训练的权重。不同于这些工作,作者探究不需要任何预训练,使用仅含自注意机制的transformer作为编码器实现医学图像分割的可行性。
作者观察到基于transformer的模型仅在大规模数据集上训练才能工作地很好。这成为了将transformer应用到医学图像任务中的主要问题,带标签图像的数量,公开可用于训练的医学数据集相对稀少。标注过程同样是昂贵且需要专业知识。具体地,用少量地图像训练导致难以学习图像中的位置编码。为此作者提出了一种门控位置敏感的轴注意力机制,介绍了四个门来控制位置嵌入提供键,查询和值的信息。这些门是可学习参数,这使得提出的机制可以应用到任何尺寸的任何数据(any dataset of any size)。根据数据集的大小,这些门可以学习到多少张图像足以学习合适的位置嵌入。基于位置嵌入学习的信息是否有用,门参数收敛到0或更大的值。进一步地,作者提出了一个局部-全局训练策略,使用了潜层的全局分支和深层的局部分支来处理医学图像的块。这个策略提升了性能,因为同时关注了整张图像和局部图像块中细粒度的细节。MedT使用门控位置敏感轴注意力作为基本块并且采取了LoGo训练策略。
文章的贡献:
- 提出了可以在更小数据集上工作得很好的门控位置敏感轴注意机制
- 介绍了局部-全局训练策略来有效训练transformer
- 由上述两种方法为基础提出了MedT来解决医学图像分割
- 在三种不同数据集上医学图像分割的性能超过了卷积网络和全注意力结构
方法
Medical Transformer
MedT采用门控轴注意力层作为基础构建块并且使用LoGo策略来进行训练。MedT有两个分支:全局分支和局部分支。这些分支的输入是由最初conv块提取的特征图(?)。该块由3个conv层组成,每层后接bn层和ReLU激活函数。在两个分支的编码器中使用了提出的transformer层,在解码器中使用了conv块。编码bottleneck层包含一个1x1的conv层,后接一个归一化层和两个多头注意力层,一头注意力处理height轴,另一头处理width轴。每个多头注意力块均由提出的门控轴注意力层组成。注意每个多头注意力块有8个门控轴注意力头。多头注意力块的输出进行了concatenated并且输入其他1*1的conv中并且与残差输入图相加生成输入注意力图。下图为详细的网络结构图。在每个解码块均由conv层后接upsampling层和ReLU激活函数。两个分支中,编码器和解码器之间均有跳跃连接。
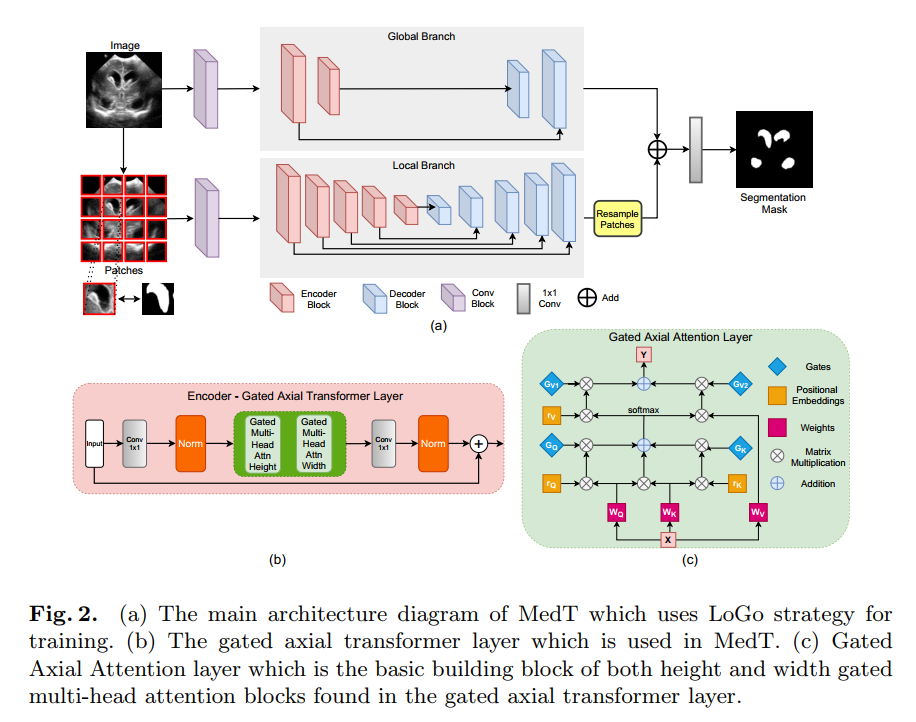
在MedT的全局分支中有2个编码块和2个解码块。在局部分支中有5个编码块和5个解码块。这些数量取决于实验分析,在验证期间不发生变换,详情见附件。
自注意力回顾
假设输入特征图为$x \in R^{C_{in} \times H \times W}$, height为H,width为W,通道为C_in。自注意层输出为$y \in R^{C_{out} \times H \times W}$,其计算方式如下公式进行映射
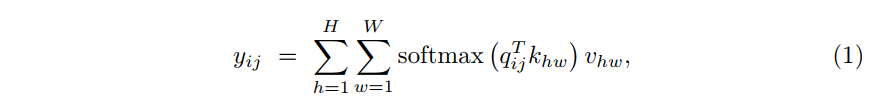
其中$q=W_Qx$,键$k=W_Kx$和值$v=W_Vx$的投影均由输入x中计算而来。其中$q_{ij}$,$k_{ij}$,$v_{ij}$表示为任意位置的查询,键和值,其中$i\in{1,…,H}$和$j\in{1,…,W}$。投影矩阵$W_Q,W_K,W_V \in R^{C_{in} \times C_{out}}$是可学习的。就如公式1,基于使用softmax计算的全局亲和力值$v$。因此,不同于传统的自注意机制有能力从整个特征图中捕获非局部信息。然而,计算这个亲和力所需要的计算力资源是非常昂贵的,并且随着特征图尺寸的增加,在视觉模型结构中使用自注意力是不可行的。此外,不同于卷积层,自注意层在计算非局部上下文时不使用任何位置信息。在视觉模型中位置信息通常对于捕获目标的结构是有用的。
轴注意力:为了克服计算机亲和力和计算复杂度,自注意被解耦成两个注意力模块。第一个模块在特征图的height轴上使用自注意力和第二个模块在width上。这是参考了axial attention。因此,在height和width轴上施加的轴注意力有效模拟了原始的自注意力机制,并具有更好的计算效率。在通过自注意机制计算亲和力时,加入位置偏置项来使亲和力对位置信息更敏感。这个偏置项通常当作是相对位置编码。这些位置编码是可训练的,并且显示出有能力编码图像的空域结构。Wang等人组合轴向注意力和位置编码提出了一种用于图像分割的注意力机制模型。此外,不同于前面仅在查询时利用相对位置编码的注意力模型,他们提出在查询,键和值中均使用相对位置编码。这个在查询,键和值中额外的位置可以用更精确的位置信息来捕获长期依赖交互。对于任意给定的输入特征图x,带有位置编码的更新后自注意力机制在width轴上可以表示成
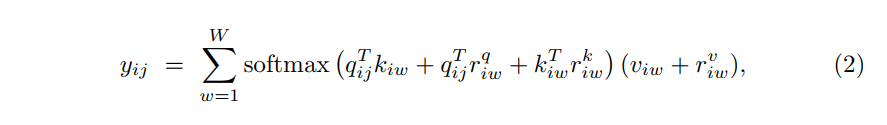
其中$r^q,r^w,r^v \in R^{W \times W}$描述width方向的注意力模型。注意公式2描述了与tensor的width一起施加轴向注意力。相似的公式也应用在height轴最后合并成计算效率很高的单个注意力模型。
门控轴向注意力
门控轴向注意力能够很高效地计算非局部上下文,能够将位置偏置编码到机制中,能够对输入特征图中的长期交互进行编码。然而,他们的模型是再大规模分割数据集上验证的,因此对于轴向注意力而言很容易学习键,查询和值中的位置偏置。作者认为使用小规模数据集,通常是医学图像分割,位置偏置是很难学习的,因此在编码长期交互时不总是准确的。在学习的相对位置编码不够准确的情况下,将它们添加到相应的键,查询和值张量中会导致性能降低。因此,作者修改了轴向注意力模块来控制位置偏置的影响从而更专注于非局部上下文的编码。在width轴上使用自注意机制的修改如下公式所示:
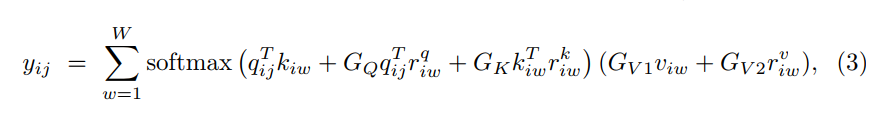
自注意力公式与使用了添加门机制的公式2较为接近。公式中G都是可训练的参数,它们一起创建了门控机制,该门控机制控制学习的相对位置编码对编码非局部上下文的影响。典型的,如果相对位置编码能准确地学习到,那么门控机制将为其指定更高的权重,反之指定更低的权重。图二(c)中显示了一个典型门控轴向注意力层的前向过程。
局部全局训练
显而易见的是在patches上训练transformer非常快,同样有助于提取图像更精细的细节。然而,仅仅patches级别的训练对于像医学图像类的的任务是不够的。这是因为分割mask将会大于Patch 的尺寸。这限制了网络学习图像块之间像素的任何信息或相关性。为了提升图像的整体理解力,提出了双分支网络,为图像原始分辨率的全局分支和图像块的局部分支。
在全局分支,减少了门控轴向transformer层的数量,这是因为作者发现仅使用少量的基层transformer就足以建模长期依赖。在局部分支,使用了16个大小为$I/4\times I/4$的图像块,I是原始图像的的维度。在局部分hi中,每个块都被喂入网络并输出的特征图被基于它们的局部信息重新采样以获得输出特征图。两个分支的特征图相加并送入1*1的卷积层中来生成最终的mask。该策略在图像的全局上下文有一个潜层模型和在patch上有一个深层的模型,以此来提升性能。因为全局分支注意高层信息而局部分支注意更精细的细节。
实验
数据集
脑解剖分割(超声)包括1300张2D的扫描图用于训练和329张用于测试,腺体分割(显微镜)85张用于训练80张用于测试以及MoNuSeg (microscopic) 30张用于训练,14张用于测试。使用单张Quadro 8000GPU来跑实验。
结果
定理分析指标使用了F1和IoU得分。提出的方法均比对比的方法好。
单词
- a preterm neonate 早产儿
- brain ventricles 脑室
- correspond to 相当于
- panoptic 全景
- To this end 为此
感悟:仍然使用卷积层来提取输入的特征图,我认为仍不能说明transformer的性能。从看的几篇计算机视觉的transformer工作来看,patches的提取很关键,至于transformer前后的卷积层作用难以说明,并且卷积层是否能被其他模型替代还有待说明。能否用transformer提取特征然后用传统的机器学习方法来做分类是否可行?