深度学习中的激活函数
导语:深度学习中,激活函数的作用非常重要。在此记录目前大多数激活函数。激活函数一律使用f(x)表示,无论其公式表示如何
1. Sigmoid
sigmoid是常用的激活函数,一般用于神经网络输出层之后,与logistic, soft step是同种类别(同名?)。在分类任务中,使用sigmoid后,得到的数值在(0,1)之间预测概率,预测概率和取决于类别数和预测概率,值可大于1。这与softmax不同,因为softmax得到的是量化后的预测结果,概率和为1,所以不需要使用阈值。激活函数的数学表示,其值域为(0,1)。

其导数为

其图像为
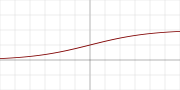
2. Softmax
softmax是sigmoid更一般的形式。它用于多分类问题。与sigmoid相似,它产生的值在0-1范围内,因此它作用与分类模型中的最后一层。其数学表达式如下,其值域为(0,1):

其导数为

3. ReLU(rectified linear unit)
中文名为整流线性单元,其常用于深度神经网络中,尤其是卷积神经网络中。其值域为[0, ∞),其公式如下

其导数为

其函数图像为
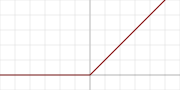
优点:
- 可以使网络更快速地收敛,计算效率很高;
- 不会饱和,因此不会导致梯度消失问题;
缺点:
- 不以0值为中心
- 在前向传播过程中,如果x<0,则神经元保持非激活状态,且在后向传播中kill梯度。这样权重无法得到更新,网络无法学习。当x=0时,该点的梯度未定义,但是在实际问题中,可以采用左侧或右侧的梯度。
4. Tanh
Tanh激活函数又叫双曲正切激活函数(hyperbolic tangent activation function)。与sigmoid函数类似,Tanh函数也使用真值。其值域为(-1,1),注意是开区间。其函数表达式为

其导数为

其图像为
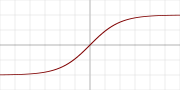
优点:
- 输出以0值为中心;
- 负数输入被当作负值,零输入值的映射接近零,正数输入被当作正值。
缺点:
- 会有梯度消失的问题,因此在饱和时也会kill梯度。
5. Leaky ReLU (leaky rectified linear unit)
LReLU弥补了ReLU在负值区域都是0的缺点,其值域为(-∞,∞),其公式如下:

其导数为

其函数图像为
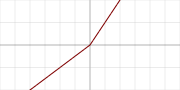
优点:该激活函数通过在x<0时引入0.01*x项,在一定程度上缓解了ReLU中负数部分神经元被杀死的问题。也拥有ReLU所有的优点。
缺点:使用该函数的记过并不连贯。
6. PReLU(parametric rectified linear unit)
PReLU在LReLU的基础上,引入了超参数a。其值域为(-∞,∞),其公式如下:

其导数为

其图像为
优点:在x<0时,引入带超参数的项a*x项,使其可以被学习。这使得神经元能够选择负区域最好的梯度,它可以变成ReLU或LReLU。
总之,在这三种激活函数时,最好使用ReLU,但是可以使用LReLU或者PReLU实验一下。
问题:使用不同初始化方法时,如图像归一化到[0,1]或者[-1,1]之间,不用的激活函数有影响吗?
7. ReLU6
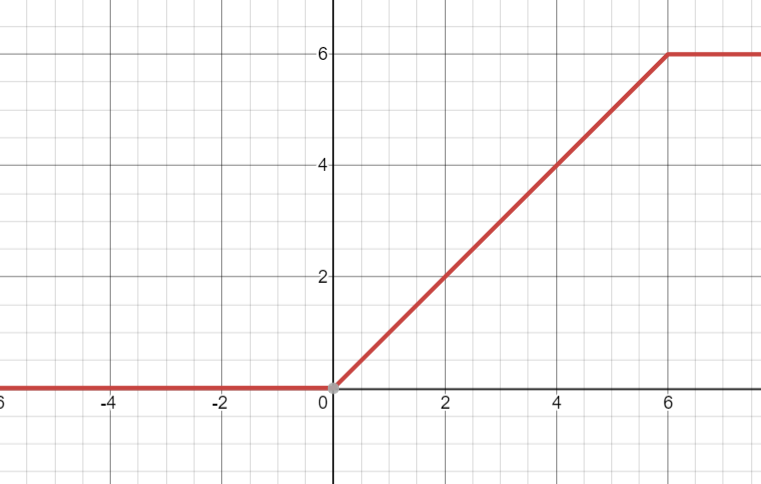
该激活函数是ReLU6的改进版本,目的在于约束正值方向的值,约束至6。其值域为[0,6],其公式如下:
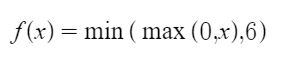
其函数图像如下:
优点:通过对ReLU正值方向进行约束,可以防止梯度爆炸。
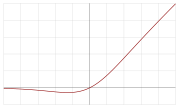
8. Swish
该函数又叫自门控激活函数,其值域为[-0.278…,∞),其数学公式为:

其导数为:

其函数图像为:
类似的改进版本有:Hard-Swish or Swish,Sigmoid shrinkage,SiL等。改进方法计算复杂度更低一点。
优点:性能上稍好于ReLU。因为它在x=0处有了导数,训练时更容易收敛
缺点:计算复杂度很高。
9. SELU(scaled exponential linear unit)
该激活函数的值域为(-λa, ∞)。其数学公式为:

其导数为:

10. Linear
线性,即函数形式为f(x) = a*x + b这种类型的激活函数
导数为f(x) = x
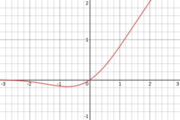
11. GELU(gaussian error linear unit)
高斯错误线性单元,其值域为(-0.17…,∞),其公式为:

其导数为:

其图像为:
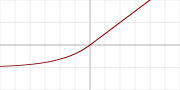
12. ELU(exponential linear unit)
指数线性单元,其值域为(-a,∞),其公式如下:

其导数如下:
其函数图像如下:
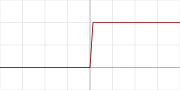
13. Binary step
二值步骤,非0即1,其值域为{0,1}。其数学公式为:

其导数为:

其函数图像为:
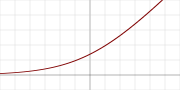
14. Softplus
其值域为(0,∞),其数学公式为:

其导数为:

其函数图像为:
15. Maxout
其值域为(-∞,∞),其数学公式为:

其导数为:

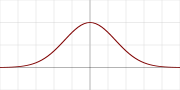
16. Gaussian
高斯激活函数,其值域为(0,1]。其数学公式为:

其导数为:

其函数图像为:
经验
- Tanh和sigmoid会导致梯度消失问题,所以不建议采用作为激活函数。
- 设计神经网络时,首先采用ReLU激活函数。通常位于CNN,RNN,LSTM,Dense层后。如果当网络出现停止学习时,使用LReLU替代来避免Dying ReLU问题。但也会增加一些计算时间。
- 如果网络中使用了BN层,那么将其置于网络层和激活函数之间,对网络层进行一个正则化操作。但是这存在争议,BN原文是CNN-BN-ReLU。
- 激活函数一般使用深度学习平台的默认值就可以得到较好的结果,LReLU中常用值是0.02。
参考资料: