论文阅读(二) A Survey on Semi-, Self- and Unsupervised Learning in Image Classification
arXiv:
摘要
在计算机视觉任务中,深度学习策略取得了瞩目的成就,但仍然有一个潜在的问题没有解决:目前的策略严重依赖巨量的标注数据集。在很多现实世界的问题中,构建如此庞大的标注训练数据集是不可取的。因此,通常将未标记数据合并到训练过程中,以减少标签数量达到平等的结果。由于进行了大量的并发研究,因此很难跟踪最新动态。在本综述中,作者回顾了在使用少量标签图像分类中常使用的想法和方法。作者从性能和常见的想法方面详细比较了33种方法,而不是细粒度的分类。在作者的分析中,分析出了三种主流趋势,这可能是未来研究的机会。(1)、在理论上,SOTA方法可以用于现实世界应用,但是没有考虑到类别不平衡、鲁棒性、或者模糊标签。(2)、为获得与所有标签的使用效果可比的结果而需要的监督程度正在降低,因此需要将方法扩展到具有可变数量类别的设置。(3)、所有方法都有一些共同的想法,但是作者确定了不共享许多思想的方法集群。作者显示了来自不同聚类想法的组合将会导致更好的结果。
背景
深度学习策略在计算机视觉任务中取得了令人瞩目的成功。它们在很多不同的领域都获得了最好的结构,如图像分类、目标检测或者语义分割。深度学习的质量受到大量标注/监督图像的严重影响。最近的研究显示比ImageNet数据集更大的数据集可以提高深度学习的性能。然而,在很多现实世界应用中,创建数百万标注图像的数据集几乎是不可能的。解决该问题常见的做法是迁移学习。迁移学习在少量且特殊的数据集领域可以提升结果,如医学成像。
多年以来,如何将这种无监督的数据用于神经网络一直是研究热点。Xie等人在2016年成为第一批研究无监督学习图像聚类策略来利用无标注数据集。从那开始,无标注数据集的使用已经经过多种方式的研究,并且创建了一些研究领域,如半监督、自监督、弱监督、度量学习(metric learning )。这些方法背后的思想是在训练阶段利用无标注数据是有益的。它可以使用少量的标注来训练一个更加鲁棒的方法,甚至在极小的领域超过了监督学习。
由于这些优势,很多公司也致力于无监督学习的研究。此类研究的主要目标是缩小半监督与监督学习的差距,甚至超过监督学习。在一些领域已经实现了对监督学习的超越。这表明,很多领域都潜在的存在这种可能。
概念
训练策略
文献中的半监督、自监督、无监督在某些方法上存在重复定义。
- 无监督学习描述了无标签数据进行训练。目标可以是数据的聚类或者好的特征表示。有一些方法组合无监督过程,如首先获得好的表示,然后进行聚类。K-mean算法是仅使用无监督学习的一个例子。
- 在大多数情况下,无监督的训练是通过生成它自己的标签来实现的,因此这些方法也被称为自监督学习。很多遵循这类范例的方法又自称为表示学习。(在本综述论文中,大多数自监督和表示学习方法需要在标注数据集上fine-tune)。由于使用了外部标注信息,因此不能将预训练和微调的组合称为无监督或自监督。
- 半监督学习描述了使用标注和无标注数据训练的方法。与表示学习相比,半监督学习方法从训练开始就使用了标注和无标注数据,表示学习在它们不同的训练阶段使用标注数据。
在文中,不再对这三种无监督学习方法进行细分,统一用reduced supervised 学习策略表示。作者将标注数据参与训练的不同阶段定义为训练过程总不同学习策略时的不同阶段/时间间隔,如在无标准数据集上进行了自监督预训练,然后再带标签的相同数据下进行微调的方法称为两个阶段;在训练阶段使用不同算法、损失、数据集但是仅在无标注数据集下训练称为一个阶段。在整个训练阶段仅使用标注或无标注数据进行训练也被称为一个阶段。基于上述定义,可以分成以下几种训练策略:
- One-Stage-Semi-Supervised: 与监督学习策略的主要差点在于使用了无标准数据集。集成无标准数据集的一种常见方法是将一个或多个无监督损失添加到监督性损失中。
- One-Stage-Unsupervised: 所有此类方法在整个训练阶段仅使用无标准数据。在大多数情况下,问题可以转换成生成所有有关说你是的输入,如在自编码器中的重建损失。自监督方法也属于此类,但是很多自监督方法属于下面一类。该类方法假定图像分类不能使用任何标注数据集。
- Multi-Stage-Semi-Supervised: 此类方法训练策略是两个阶段的训练。第一阶段使用无标注数据训练,第二阶段使用标注/无标注数据训练。很多自监督学习方法都是作者自称的。通常,前置任务是学习五标注数据中的表示。在第二阶段,这些表示被fine-tuned到标注数据图像分类中。与单阶段方法的重要区别在于,这些方法仅在额外训练的阶段之后才返回可用的分类。
共同思想(Common idea)
需要注意的是,我们对共同思想在定义上是模糊且不完整的。将从两个方面来介绍:损失函数和通用概念。
损失函数
-
Cross-entropy(CE)
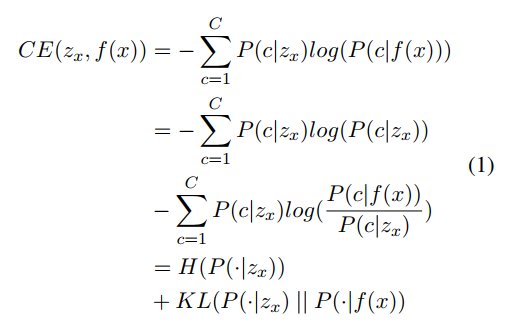
-
Contrastive Loss(CL)
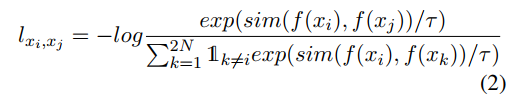
-
Entropy Minimization(EM)
-
Kullback-Leibler divergence(KL)
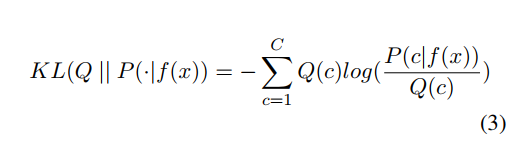
-
Mean Squared Error(MSE)
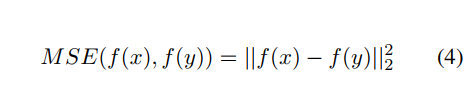
-
Mutual Information(MI)
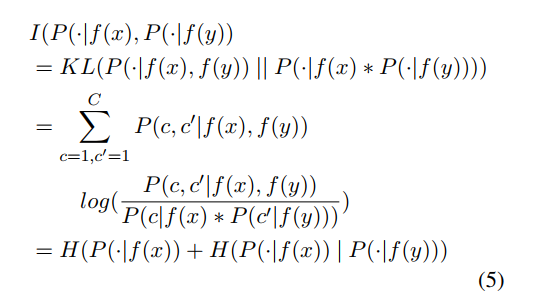
-
Virtual Adversarial Training(VAT)
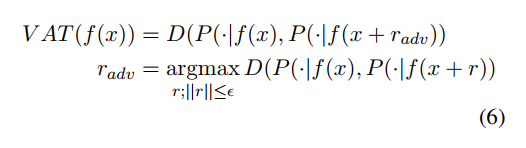
概念
-
Mixup(MU)
-
Overclustering(OC)
-
Pretext Task(PT)
-
Pseudo-Labels(PL)
比较(Comparison)
我们将分析哪些共同的想法在方法之间是共享的或不同的。 我们将在通用的深度学习数据集上比较所有方法的性能。
数据集
- CIFAR-10和CIFAR-100:
- STL-10:
- ILSVRC-2012:
评估指标
对于无监督学习,使用聚类准确率,因为需要在训练时处理缺失标签。需要预测真正的聚类。