导语:这是发表在2019年CVPR workshop上的一篇对抗样本攻击的研究,攻击的是自动监控相机。具体而言是用对抗性补丁来攻击行人检测
论文地址:https://ieeexplore.ieee.org/document/9025518
github: https://gitlab.com/EAVISE/adversarial-yolo
摘要
在最近几年机器学习模型的对抗攻击得到了快速的发展。通过仅细微地改变卷积神经网络的输入,网络的输出就能够被摇摆不定成输出完全不同的结果。第一个攻击通过轻微地改变一个输入图像的像素值来欺骗分类器输出错误的类别。其他方法则尝试学习“补丁”,然后将该补丁应用到某个物体上来欺骗检测器和分类器。这些方法中的一些也显示出可将这些攻击应用到真实世界中,例如,通过修改物体并用相机去拍摄它。然而,所有这些方法都针对几乎不包含类内多样性的类(例如,停止标志)。然后使用对象的已知结构在其上生成对抗性补丁。
在本文,我们提出了一种为具有大量类内多样性的目标生成对抗性补丁的方法,也就是人类。目标是生成对抗性补丁,该补丁能够成功地隐藏人,从而避免行人检测器的检测。例如,可能被恶意用于绕过监控系统的攻击,通过手持小的硬纸板置于他们身体前面面对着监控相机,入侵者可以在不被发现的情况下偷偷溜走。
从我们的结果可以看出,我们的系统能够很大程度上降低行人检测器的检测成功率。我们的方法在由相机拍摄补丁的真实生活场景下也表现得很好。就我们所知我们是第一个尝试对具有高度类内多样性的目标(例如人)进行这种攻击的人。

1 Introduction
在计算机视觉领域CNN取得了巨大的成功。数据驱动的端到端管道的CNN在图像的学习已经被证明在很多计算机视觉任务中都能得到最佳的结果。由于这些结构的深度,神经网络从网络的底层(数据输入层)可以学习到非常基础的滤波器,到顶层可以学习到非常抽象的高层特征。为实现上述目的,典型的CNN包含了数以百万计的学习好的参数。这种方法会产生很高成功率的模型,但是却严重降低了可解释性。理解为什么网络会将一张人的图像分类成人是非常困难的。网络通过看到很有其他人的图片学习到了人应该长成什么样。通过验证模型,我们可以通过比较它和人类标记图像来判断模型工作的好坏。然而通过这种方式验证模型只能高斯我们某个检测器在特定测试集上的好坏。此测试集通常不包含旨在以错误方法指导模型的示例,也不包含特别针对愚弄模型的样本。例如,这适用于不太可能受到攻击的应用程序,例如老年人跌倒检测,但是可以对于安全系统来说却是个问题。监控系统中的人体检测模型的脆弱性可能被用于绕过用于防止建筑物内的破坏的监控摄像头。
在本文,我们强调了这种对人员检测系统的攻击的风险。我们创建了小的(大概40cm x 40cm)大小的对抗性补丁来作为一种伪装设备将人从目标检测器下隐藏。
论文的剩余部分安排如下:第二部分回顾了对抗样本攻击的相关工作。第三部分介绍了我们如何生成这些补丁。第四部分我们在Inria数据集上进行定量评估,我们在拿着补丁时拍摄的真实视频片段进行了定性评估。
2 相关工作
随着CNN的受欢迎度不断提升,在过去的几年CNN的对抗性攻击的热度也不断增长。在本节,我们回顾了这些攻击的历史。我们首先讨论了在分类器中的数字攻击,然后讨论人脸识别和目标检测中的真实世界攻击。然后我们简单讨论了目标检测器,在本文中我们的攻击目标是YOLOv2。
- 分类任务中的对抗性攻击:
- 2014年 Bigio等人【2】现实了对抗性攻击的存在。
- 随后,Szegedy等人【19】成功地攻击力了分类器模型。他们使用一种可以欺骗网络做出错误分类图像的方法,仅需要轻微地改变图像中的像素值,然而这些改变对人眼是不可见的。
- 随后,Goodfellow等人创建了FGSM方法,使在图像上生成对抗样性攻击的速度更快。与找到最优图像的方法【19】相反,他们在更大的图像集中找到能够对网络进行攻击的单个图像。
- 在【14】中,Moosavi-Dezfooli等人提出了一种算法能够通过更少地改变图像来产生攻击算法,并且比以前的方法更快。他们使用超平面对输入图像的不同输出类之间的边界进行建模。
- Carlini等人【4】提出另一种对抗攻击,使用了优化算法。与已经提到的算法相比,他们提高了图像的成功率和差异(使用不懂范数)。
- 在【3】中,Brown等人创建了一种方法,与直接改变像素值的方法不同,生成的补丁可以数字化放置在图像来欺骗分类器。与使用图像相反,他使用多样的图像来建立类内鲁棒性。
- 在【8】中,Evtimov等人提供了一种攻击真实世界分类器的方法。他们针对停止标识分类的任务,该任务由于停止标识可能出现的不同姿势而变得具有挑战性。他们生成了一中贴纸然后将它们贴到停止标志上使其不会被识别成停止标志。
- Athalye等人【1】提出了一种优化3D模型纹理的方法。通过优化不同姿势的图像来建立一个对不同姿势和光照变换鲁棒的图像。结果对象使用3D打印器打印出来。
- Moosavi-Dezfooli等人的工作【13】提出了一种生成单个通用图像的方法,该方法可以用于不同图像的对抗性扰动。通用对抗性图像同样现实出对其他检测器的鲁棒性。
- 真实世界中的面部识别的对抗性攻击:真实世界对抗性攻击的一个例子是【17】。Sharif等人证明了使用打印出的可以欺骗面部识别系统的眼镜。为了保证眼镜需要在各种不同姿势下的鲁棒性。它们以在大规模数图像集合上,而不是在单张图片上优化眼镜的方式。他们同样包括了一种非打印得分(Non Printability Score, NPS),这使得图像中的颜色可以被比打印机表示。
- 真实世界中目标检测的对抗性攻击:chen等人【5】提出了一种真实世界攻击来攻击目标检测。他们针对基于Faster R-CNN检测器中的停止标志的检测器。像【1】一样,他们使用了EOT(在图像上进行了不同的变换)来建立对不同姿势鲁棒的攻击。最近的工作是欺骗真实世界中目标检测的Eykholt等人【18】。在该文中,他们针对停止标识,并使用YOLOv2检测器来作为一个白盒攻击,他们在停止标志的整个红色区域填充某种模式(pattern)。他们同样在Faster-RCNN上进行验证,并且发现他们的攻击可以应用到其他检测器。
与本工作相比,其他所有攻击目标检测的工作聚焦在以固定视觉模式(如交通标志)的固定物体上,并未被考虑进到类内差异中。就我们所知,目前还没有提出在多种类别(如人员检测)检测方法的工作。
目标检测:在本文中,我们针对最受欢迎的YOLOv2目标检测器。YOLO适用于更大类别的单次目标检测器(与SSD等检测器一起使用),其中边框,目标分数和类别分数是通过单次传递直接预测的。YOLO是完全卷积的,输入图像被传入网络,其中各层将其缩减为比原始输入分辨率小32倍的输入网络。输出网格中的每个单元均包含5个预测点(称“锚点”)表示包含不同横纵比的边框。每个锚点包含一个向量$x_{offset},y_{offset},w,h,p_{obj},p_{cls1},p_{cls2},…,p_{clsn}$, $x_{offset}$和$y_{offset}$是边界中心相对于当前锚点的位置,w和h是边框的宽和高,$p_{obj}$是锚点包含目标的概率,$p_{cls1-n}$是使用交叉熵损失学到的目标类得分。图2显示了结构的大致框架。

3 生成针对人员检测的对抗性补丁(Approach)
本工作的目标是创建一个系统,该系统能够生成用于欺骗人员检测的可打印对抗性补丁。如早期所讨论的,Chen等人【5】和Eykholt等人【18】已经显示了在真实世界中对目标监测器的对抗性攻击是可能的。在他们的工作中针对的是停止标志,在本文我们则针对人员检测,不同于停车标志的统一外观可以变化更多。使用一种优化方法(在图象素),我们尝试找到一种补丁,在大规模数据集上,有效地降低人员检测的成功率。在本部分,我们将深度解释生成这些对抗性补丁的过程。
我们的优化目标包含以下三个部分:
- $L_{nps}$:非打印得分[17],一种表示如何更好地由通用打印器表示在我们补丁中的颜色。由如下公式给出
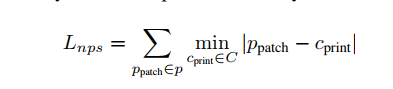
其中$p_{patch}$是补丁P中的像素,$c_{print}$是可打印颜色C中的一种颜色。该损失有利于使我们图像中的颜色更靠近可打印颜色集合中的颜色。
-
$L_{tv}$ 在文献【17】中描述的图像中的总变化。该损失确保我们的优化器有利于具有平滑颜色过度的图像,并防止出现噪声图像。我们从一个补丁P中计算该损失的过程可以表示称:
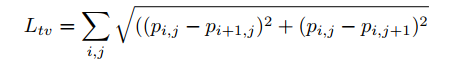
如果邻近像素很相似,那么该得分将会很低,如果邻近像素不同那么该得分将会很高。
-
$L_{obj}$图像中最大的目标性得分。我们补丁的目的是隐藏图像中的人。为实现该目的,我们训练的目标是最小化由检测器输出的目标或类别得分。该损失将会在接下来的部分详细讨论。
在这三部分中我们遵循的总损失函数: \(L = \alpha L_{nps} + \beta L_{tv} + L_{obj}\) 我们计算这三个损失的和,其中权重由经验性的决定,使用Adam算法进行优化。
我们优化器的目的是最小化总损失L。在优化阶段,我们冻结网络的所有权重,仅改变补丁中的值。在优化开始阶段,我们使用随机值对不对进行初始化。
下图是目标损失计算的大致过程。计算类别概率的过程相同。在本节的其他部分,我们将深度解释它是如何工作的。
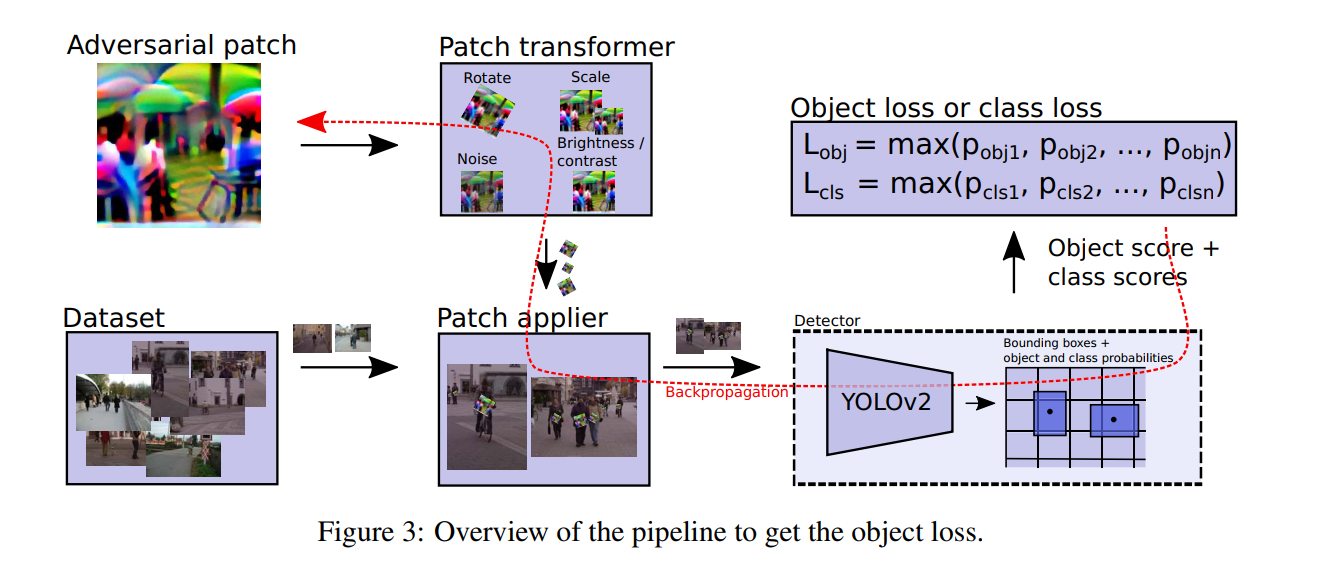
3.1 最小化检测器的输出
正如第二部分解释的,YOLOv2目标检测器输出一个单元网格,每个网格包含一系列锚点(默认是5个)。每个锚点包含边框,目标概率和类得分。为达到使检测器忽略人员的目的,我们以三种不同的方法进行实验:我们既最小化人员的分类概率(或最小化目标得分),或包含二者。我们尝试了所有方法。最小化类得分的趋势是将人的类转换到其他不同的类。在我们的实验中YOLO检测器在MS COCO数据集上进行训练【11】,我们发现生成的对抗性补丁会倍检测成COCO数据集中的其他类。然而开始与其他类别类似的补丁,补丁迁移性不如在没有包含类别数据集上训练的模型。
我们提出的最小化目标得分的其他方法没有这个问题。尽管在训练时,我们仅将补丁放在人员的上面,相比于其他方法,结果补丁对特定类别不那么由针对性。

3.2 准备训练数据
与之前在停止标志符【5,19】上的工作相比,为人的类别创建对抗性补丁更具挑战性:
- 人的外观非常差异很大:衣服,肤色,身高,姿势等。而停止标志符号通常只有一种八角形形状,并通常是红色。
- 人们可能出现在不同的环境中。停止符合大部分情况下出现在相同的街边场景。
- 人的外观将依赖于一个人是否看向相机。
- 在人身上,没有可以放置我们补丁的一致性的地方。在停止标识上,很容易计算补丁的实际位置。
在这部分,我们解释了我们如何处理这些挑战。首先,与[5,18]中人工修改目标对象的单张图像并进行不同比转换不同,我们使用了不同人的真是图像。我们的工作流是:我们首先在图像数据集上运行目标人员检测器。更具检测器生成了出现在图像中的人的边框。在相对于这些边界框的固定位置上,我们然后将当前版本的补丁应用于不同变换下的图像。然后将结果图像喂入检测器。我们测量了仍倍检测的人员的得分,这用于计算损失函数。在整个网络上使用反向传播,优化器将进一步修改补丁中的像素以欺骗检测器。
该方法的一个有趣的副作用是我们没有限制于某个标注的数据集。任何收集的视频或图像都可以被喂入目标检测器来生成边界框。这允许我们的系统实现更多的目标攻击。当我们拥有来自不同环境的可用数据时,我们的目标是我们可以简单的使用该镜头来生成针对该场景的补丁。这样做的效果可能比通用的数据集更好。
在我们的测试中,我们使用了Inria数据集的图像。这些图像更针对全身行人,这更适合我们的监控摄像机应用。我们知道可以使用更具挑战性的MS COCO和 Pascal VOC数据集,但是这些数据集包含更多的人员出现的差异(如一只手臂被标记成人),这是使得很难以一致性的位置放置我们的补丁。
3.3 使补丁更加鲁棒
在本文中,我们的目标补丁可以应用到真实世界中。这意味着它们首先被打印出来,然后由视频相机进行录制。当你制作补丁时,有大量的因素可以影响补丁的外观:光线的变化,补丁可能发生轻微的旋转,与人相关补丁的尺寸可能发生变化,相机可能有噪声并对补丁产生轻微的模糊,视角有可能不同等等。为了尽可能考虑到这些因素,在将其应用到图像前,我们在补丁上进行了一些转换。我们进行了如下的随机转换:
- 补丁在每个方向旋转了20度。
- 补丁被随机缩小和放大。
- 在补丁上添加随机噪声。
- 随机改变补丁的亮度和对比度。
在整个过程中,重要的是要注意,必须始终可以计算所有的操作对补丁的反向梯度。
结果
在这部分我们验证了我们补丁的有效性。我们通过使用与训练时相同的过程将补丁应用到Inria测试集上来验证我们的补丁,包括随机转换。在我们的实验中,我们尝试最小化可以潜在的隐藏人的少量不同的参数。作为控制,我们以相同的方式,比较了包含随机噪声的补丁。下图展示了不同补丁的结果。
OBJ-CLS的目标是最小化目标得分和类别得分的乘积,OBJ仅是最小化目标得分,CLS仅最小化类别得分。NOISE是我们控制的随机噪声补丁,Clean是没有使用补丁的baseline(我们通过运行相同检测器在数据集上生成的边界框得到了最优的结果)。从这个PR曲线我们可以清晰的看到生成补丁与随机噪声补丁的影响。我们同样可以观察到与最小化类别得分相比,最小化目标得分有最大的影响(最低的平均准确率(AP))。
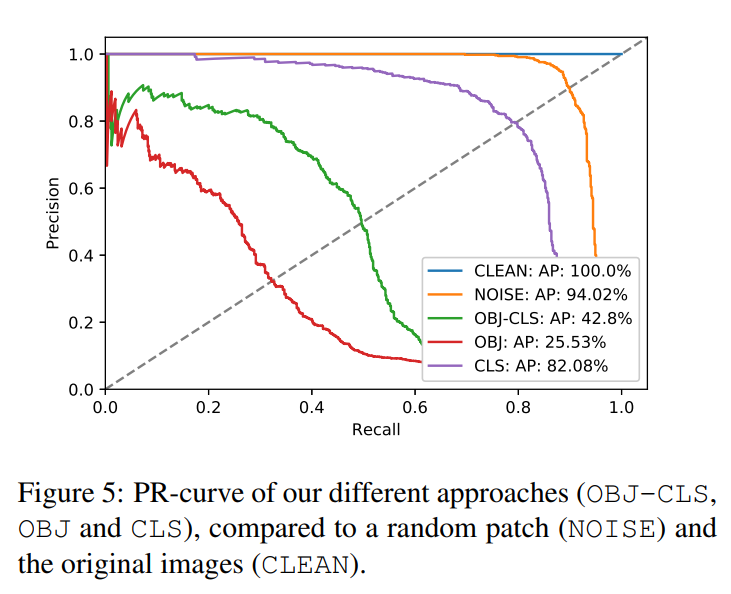
确定PR曲线上用于检测的良好工作点的典型方法是在PR曲线中绘制对角线,并且观察在什么地方与PR曲线相交。如果我们在CLEAN的PR曲线上做这件事,我们可以在那个良好工作点上使用结果阈值(在我们的样例中是0.4)作为参考来观察我们方法低于检测器召回值的程度。换句话说我们要问这样的一个问题:监控系统产生的警报中有多少是通过使用我们的补丁来规避的?表一展示了上图中简写的分析的结果。从中我们可以很清晰的看到我们的补丁在很大程度上降低了生成的警报。
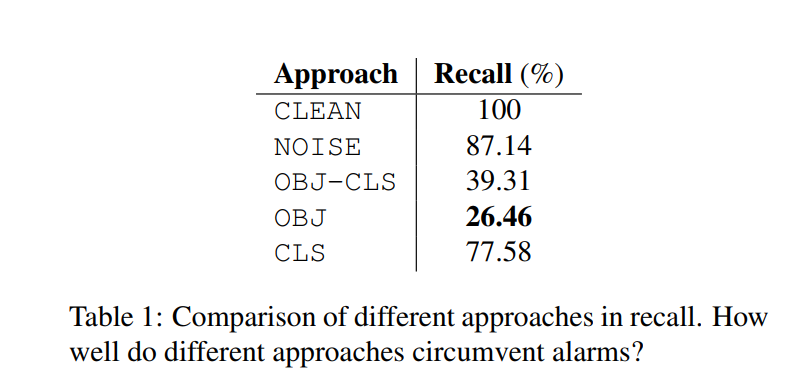
图6展示了在Inria测试集中应用到一些图像的补丁例子。我们应用YOLOV2检测器检测了不带补丁的图像(第一行),带随机扰动补丁(第二行),使用我们生成的最佳补丁(OBJ,第三行)。在很多情况下我们的补丁有能力成功地将行人从检测器下隐藏。情况并非如此,补丁并不是对齐在人的中心。这可以如下事实解释,在优化阶段,补丁仅在由边界框决定的人的中心位置。

图7我们测试了我们补丁的打印版本在现实世界中是如何工作的。通常补丁看起来工作的很好。由于补丁是在相对于将补丁保持在正确位置的边界框的固定位置上进行训练的事实似乎非常重要。

5 结论
在本文,我们提出了一个生成对抗性补丁的系统来欺骗人员检测器,该补丁可以被打印出来并且在真实世界中使用。我们通过优化图像来最小化检测器输出中人员外观相关不同概率来实现。在我们的实验中 ,我们比较了不同方法并且找到了创建最有效补丁的最小化目标损失。
从我们打印出来的真实世界测试补丁,我们同样可以看到我们补丁在从目标检测器下隐藏人员工作的很好,这表明使用相似检测器的安全系统可能对于此类攻击非常脆弱。
我们相信,如果我们与有经验的衣服采访合作,将这种技术应用到服装中,我们可以设计一种T-shirt印花,可以使人员从自动监控摄像机下不可见。
6 未来工作
在未来,我们将这些工作拓展的更加鲁棒。一个方法是通过在输入数据上使用更加放射的转换,或使用仿制数据。其他的一个方面是使得工作更具可转移性。我们当前的补丁在完全不同的结构上(如FASTER R-CNN)表现得不是很好,同时对不同的结构进行优化将会提高可迁移性。
词汇
- sway 摇摆不定地
- cardboard plate 硬纸板
- sneak around 偷偷摸摸
- This is fine for application where attacks are unlikely such as for instance fall detection for elderly people. 这适用于不太可能受到攻击的应用程序,例如老年人跌倒检测。
- cloak 伪装
- quantitatively 定量
- qualitatively 定性
- go over 过去(回顾?)
- favours 有利于
- a grid of cells 单元网格
- Where this is not the case 情况并非如此